#lucas and max however a tricky
Explore tagged Tumblr posts
Visit Tumblr Blog
Explore Tumblr blogs with no restrictions, modern design and the best experience.
Last Seen Tumblr Blogs





Fun Fact
The average Tumblr user visits about 67 pages every month.
Text
I know Hogwarts Houses are not the thing to do anymore, but I came across someone who called Nancy Wheeler a Slytherin, and my brain wouldn't rest until I figured out what she would actually be.
It's not that Slytherin wouldn't be a logical choice in some ways. Nancy certainly has a strong desire to prove herself and plenty of ambition. However, those things are not what drive her, what motivate her.
Nancy would think that she's a Ravenclaw. She highly values truth and knowledge, but it's a means to an end for her. It's not the end goal itself. Knowledge is important to her because of what it gives her, the power and ability to act, and to make a difference.
She is highly like Hermione in this way, but therein lies my reasoning for ultimately choosing Gryffindor. Nancy, for all her intelligence, can be the most reckless, dunderheaded ball of loyalty and courage in the world. She can be a straight-up battering ram when rules she usually respects get in her way. Her motivation ultimately ends up being centered on justice and protectiveness.
Her ambition comes from a desire to be someone who can make a difference in the world; who can be seen for who she actually is, but also just because she cares. She wants to help people, and she'll use any means she can think of to do so (legal or not, lol)
#hufflpuff also focus on loyalty#but Nancy’s brand of loyalty is more emotionally distant and more action based#than their type#she cares but she certainly isn't the cuddly let people in type#i actually think very few of the hawkins kids are Gryffindor aside from Nancy#so this isn't a they're all brave and therefore Gryffindor thing#dustin is 100% Ravenclaw#steve mike and will are hufflepuff#robin would be Ravenclaw#el... hmm maybe Slytherin#as weird as that sounds she's highly self centric focused just because of the way she was raised#she's not recklessly courageous or particularly friendship based#she cares about HER people and honestly thats about it#the boys are the ones who keep pushing her into the “Hero” role when she just wants to live her life#erica is 100% slytherin#lucas and max however a tricky#I could see them both as Gryffindors#lucas is the protector kind of loyal where as mike is the friendship glue kind of loyal#and max's upbringing taught her to value strength and the image of courage as a shield#she is loyal to any who prove their trustworthiness to her and will fight any monster that stands in her way#she's not out for truth and knowledge or ambition or power#just love#Jonathan is Ravenclaw#some people may be surprised by that choice when he is exceedingly loyal and brave#but look at what he's interested in when he takes photographs and think about how he limits his loyalty to his family and the few they love#he loves watching the world and dissecting it because he likes to understand things#not just to gain anything from it#nancy wheeler#stranger things#i do understand that my opinions on the characters are not the end all be all so if you have other thoughts and takes please share them
11 notes
·
View notes
Note
Hii its me crow anon!! I've been wondering what charaters do you see tracy and violetta being friends with :3 do they have any friends in common? Are there some people where the other kinda feels like "i think you shouldnt hang around with that one the vibes are off"?
Yeah! Here they are. I wrote a a lot lol (⌒-⌒; ) Hope it answers your questions
Tracy’s friends are Luca, Charles, Victor (sort of), and Alva (sort of)
Victor because I like to think he was the local mailman of the area. He knew pretty much everything about the “accident” with her father and was the kindest to her during those tough times. I say “sort of” because 1) they don’t really see each other much 2) Victor is /very/ secretive of his life, and she often feels like she doesn’t really know much about him which was upsetting.
Luca is her closest friend. Sees him as her best friend and as a brother at the same time. She met him before his arrest and they developed a relationship really fast because of their similar interests, careers, and personalities. After his arrest, that didn’t change. Meeting him again in the manor, however, their relationship sours but she still doesn’t let him go.
She didn’t meet Charles until she arrives at the manor. They didn’t know each other but similarly to Luca they got close quickly because of their interests . She also wanted to help him with his terrible self esteem and attitude towards his work. He’s also the reason the relationship between Luca and Tracy soured .. cause Luca was being a dick towards him and Tracy stood by Charles’s side.
She met Alva through Luca. She was intimidated by him but also fascinated by literally everything he does. They couldn’t meet often because they both lived in completely different parts (Alva in an affluent area while Tracy in a middle class common area) . Her respect for Alva was lost after Luca’s arrest.
For Violetta, she’s friends with Margie, Murro, and the rest of hullabaloo (but it’s really just Margie and Murro but she’s unaware)
Margie and Violetta have a bittersweet relationship. They do things like each others makeup, dress up, sing, and regular chatting. Sometimes Margie would sleep in Violetta’s room whenever she was too uncomfortable with Sergei, and she’s the only person she could trust to do that. But Violetta, ignorant to what’s going on between Margie and Sergei, often praises him for his excellent performances which turns Margie vexed. They also have this fall out and it’s because of Sergei. All of their problems stem from Sergei. They started talking less and Margie got caught up in her problems.
I think the friendship between Murro and Violetta can be easily explained.. Unfortunately he leaves the circus and Violetta isn’t left with anyone
Some friends they have in common would be Margie, Murro, and Luca (like how Luca was gushing about Alva to Tracy end then he later introduced her to him. Tracy was doing the same thing but with Violetta lmao) Tracy has a rather interesting relationship with Margie. I want to illustrate it sometime soon.
For “I think you shouldn’t hang around with that one the vibes are kind of off,” it would probably Tracy to Violetta with Mike, Sergei, and Bernard.
Mike just unsettles Tracy. And the way Mike (sometimes) speaks towards Violetta can be rather condescending. He’s just a little scary. Put on contacts please
Sergei. Know how I said Tracy and Margie have an interesting relationship? They’re pretty close, and Tracy knows all about the kind of man he is. She does not want her around that man
Bernard is a tricky one.. because Violetta wants to get closer to him and make him proud, something she couldn’t do with Max. But Tracy knows how Bernard feels about Violetta. He’s so comfortable making crude jokes about her with Tracy thinking that she’ll be amused. Tracy does eventually tell her how much she really dislikes Bernard, and Violetta.. actually agrees, but she still has this hope that he can see her efforts and embrace her as a star. Tracy wishes Violetta could open her eyes.
Violetta likes Tracy’s friends so she has no qualms with them
Honorable mentions:
Tracy and “Vera”: not necessarily friends.. but they’re cool with each other, I guess. Around the area of the circus is the perfume store Vera owns. Tracy goes there because after seeing Violetta, she grew this urge to take care of herself more, and it’d be nice to not smell like book dust and metal.
Violetta and Galatea
… kill me. Can’t think of anymore. I do plan on drawing these friendships
#asks#this is like. All in a headcanoned world I made in my head#sorry if there any grammar mistakes! I hope it’s all legible
1 note
·
View note
Text
XXXXXXXXXXXXXXXXXXXXXX
Listen, i've said it once, and I'll say it again. Mike constantly fucks up Vecna's plans. Who figured out the upside down in season one? Mike. You could be like, "Oh, no, it was ALL El, or it was a group effort." And it was a group effort. But fact of the matter is, if Mike was like Dustin and Lucas, El would have been sent off back to the government just like that. However, Mike gave El a chance and it saved Will. (who we can gather that's who's Vecna is is gunning for.) He gave El a name that wasn't a number, and started her on her way to becoming her own person. in season one, Mike was the domino that fucked up Vecna's plans.
Season two? The entire Mindflayer. Joyce didn't understand nada about that, also she could barely get Will to confide in her, However with Mike? Just like that. Boom, Mike had Will spilling everything too him. Also, Mike sat with Will in the hospital room, sorta helped in the hospital when everything went to shit. Then, when Will got possessed he was the one that got through to him. Not Joyce, not Jonathan, Mike. Then, after that, he brings El back. El came back for her friends but she's focused all on Mike most of this season, like we can put two and two together here. Mike brought El back to hawkins, thus putting Vecna on the losing side. Eleven is their trump card, if El is in Hawkins, Vecna ain't doing SHIT. Also, even after all of this. Mike is the one who proposed the tunnels and lighting those things on fire. he's the one who rallied the group and made them go. He put ANOTHER handicap on Vecna's plans.
Season 3 is a bit tricky, but Mike is the one who figured out Billy like right on the spot. Also, while he did hurt Will and Eleven this season, he fixed it. Not only showing that if Vecna wanted to separate them, he'd have to do more then some petty drama, but uniting the party once again for the final battle. Think of it, I've talked in the past how El was in the wrong for spying on Mike, but Mike is the one who apologized. Mike, even when scared, takes initiative. If Vecna were to trap him in his nightmares, but Mike saw one of his party in distress, he would get over his nightmares. This season ends with the Byers dipping out of Hawkins, which is a big win for Vecna. not only are two of the worst threats to his plans off the board, the third is wallowing and at 100%. This is when he makes his move, taking Max off the board.
Max is the only one of the party that if Mike were to die, she would be able to fufill that leader postion since they are two sides of the same coin. Vecna knew that and pre-emptively picked her off the board. Because, with all this evidence, why would he gun for Mike first? He wasn't talking to Will, he was lying to Eleven, he was distant with the rest of his party. it would be so easy for Vecna to just take him off the board, but Max was the thing that would fuck it up for him if he did. So, by taking Max out, he weakens the party and it gives him more control over Mike because of how he would feel about that.
Now, moving onto season 4. As much as I hate to say it. I DO think Mike's speech helped just a bit, just a small bit. But even if it didn't, Mike's actions "made" (I'm saying made but in reality, it just swayed her decision a bit more then if he didn't do that shit.) El get her powers back. He brought both El and Will back to Hawkins, along with whatever party was missing at that point. Once more, Mike fucks up Vecna's plans.
If we think about it this way, of course Vecna would be stalking the fuck out of him. He's be like. "alright, this kid keeps fucking up my plans, he keeps figuring everything out and bringing everyone with him, he keeps bringing Will and El back. I'm going to torment the fuck out of him and monitor him at all times until I can get rid of him." He wants Mike out of the picture, and what better way to do that is to make him paranoid, agitated, and be aware of everything he's doing so he can plan Mike's next move.
forever thinking of every breath you take being used as a song because the ending bit is literally just vecna watching mike
every breath you take

every move you make



every bond you break



every word you say



every vow you break


every smile you fake


i'll be watching you






359 notes
·
View notes
Text
welcome to my stimboard kin blog !!
about the mod:
hey, i'm mod raven! my pronouns are he/him, i'm 16 and i'm biromantic, asexual and transgender. i have depression, social anxiety, generalized anxiety, paranoia, add and insomnia, so i'm really sorry if i'm not always super active-
my favorite stims are crystals, dice, knives, soap cutting, pokemon cards and slime stims !!
you can find more bellow the cut~
rules:
-please be patient
-i have the right to deny any request
-read everything before requesting, please!
-do not repost/claim my stimboards as yours
-please only send one request per ask. feel free, however, to send as many individual requests as you want/need, just don't spam/send the same request over and over again!
-don't send any requests if they're closed! /gen /nm
-respect my blacklist and dni, please
-i won't do outside sources, sorry!
before you request:
-please tell me the colours/theme and which stims you would like me to include.
-if there are any things you specifically don't want to be included (for example hands, knives, etc.), please tell me so as well.
sources i'll do:
-danganronpa
-death note
-fullmetal alchemist: brotherhood
-ghost eyes
-hooky
-i'm the grim reaper
-it (2017)
-lalin's curse
-lumine (webtoon)
-my hero academia
-omori
-otherkin/therian
-pjo, hoo, toa (rick riordan's book series)
-pokémon
-she-ra
-stranger things
-studio ghibli
-the promised neverland
-tokyo ghoul
-vocaloid
-voltron: legendary defender
dni if you are/support:
-anti lgbtq+/exclusionists
-anti neopronouns
-map/nom*p (a)/pear/p*do (e)/etc
-factkin
-anti-kin
-t*rf (e)/r*dfem (a)/sw*rf (e)
-ab*se (u), inc*st (e), ped*phillia (o), etc
-r*cist (a)
-s*xist (e)
-transm*d (e)/tr*sc*m (u, u)
-super straight/super gay/etc
-trump supporter
-pro-shipper/anti-anti
-yandere
-chihiro fujisaki gender discourse (i'll be using they/them!)
-discourse in general
-kink/nsfw main blog
-cg/l, cg/lre
-any other basic dni criteria i might've missed
(i'm censoring some of the words so they don't show up in tags or something-))
whitelist:
~danganronpa: (characters) kokichi ouma, korekiyo shinguji, maki harukawa, rantaro amami, shuichi saihara, nagito komaeda, chihiro fujisaki (ships) saiouma
~death note: (characters) l lawliet, light yagami, mello, near (ships) lawlight, meronia
~fullmetal alchemist: brotherhood: (characters) edward elric, alphonse elric, ling yao, lan fan, mei chang, envy (ships) edling, almei, lan fan x winry
~ghost eyes: (characters) tobias schneien, mattias schneien, emilio murkmere, rudolph richardson, francis delacruz, dwayne londi, luther schneien, simon louis (ships) tobias x emilio, rudy x carmelo, dwayne x francis
~hooky: (characters) damien wytte, dorian wytte, dani wytte, william, monica, nico, mark, carlo (ships) damien x william, dani x nico, dorian x monica
~i'm the grim reaper: (characters) brook, scarlet, chase
~it (2017): (characters) richie tozier, eddie kaspbrak, beverly marsh, georgie denbrough (ships) reddie
~lalin's curse: (characters) david, felix, cody, (ships) david x cody
~lumine: (characters) kody, lumine, calla (ships) kody x lumine
~my hero academia: (characters) tsuyu asui, denki kaminari, eijirou kirishima, kyoka jirou, shoto todoroki, izuku midoriya, tamaki amajiki, hitoshi shinso, eraser head, hawks, tomura shigaraki, dabi, eri, kota izumi (ships) tododeku, kiribaku, erasermic, kamishin, tsuchako
~omori: (characters) sunny/omori, basil, mari, hero, kel, aubrey (ships) sunnflower (basil x sunny), picnic basket (hero x mari), baseball bat (kel x aubrey)
~pjo, hoo, toa: (characters) percy jackson, nico di angelo, will solace, hazel levesque, leo valdez, meg mccaffrey, grover underwood, thalia grace (ships) solangelo, percabeth, frazel, caleo, theyna
~pokémon: (characters) ash ketchum, gladion, lillie, drew, max, hau, allister, mallow, lana, pikachu (ships) ash x gladion
~she-ra: (characters) double trouble, catra, adora, glimmer, bow, lonnie, kyle (ships) catradora, glimbow, repkylonnie (kyle x lonnie x rogelio)
~stranger things: (characters) eleven, max mayfield, mike wheeler, will byers, dustin henderson, kali prasad, robin buckley, steve harrington (ships) byler, harringrove, elmax, mileven
~studio ghibli: haku, chihiro ogino, satsuki kusakabe, mei kusakabe
~the promised neverland: (characters) norman, ray, emma, gillian, lucas, mister/yuugo (ships) norray, yuucas, gildemma
~tokyo ghoul: (characters) ken kaneki, ayato kirishima, touka kirishima, hide nagachika, juuzou suzuya, hinami fueguchi, uta, kuki urie (ships) ayakane, touken, mutsurie, uta x yomo
aesthetics:
-adventurecore
-arcadecore
-cottagecore
-cryptidcore
-fairycore
-gremlincore (don't use the term g*bl*ncore (o, i) on my blog, please, as that term is considered ant*sem*t*c (i, i, i))
-kidcore
-lovecore
-starcore
-witchcore/witchy aesthetic
blacklist:
~danganronpa: (characters) korekiyo shinguji's sister, haiji towa, hifumi yamada, teruteru hanamura (ships) kokichi ouma x girls, nagito komaeda x girls, tenko chabashira x boys, saimatsu, oumeno
~death note: yagamane
~fullmetal alchemist: brotherhood: (characters) father (ships) edroy
~ghost eyes: lucas schneien, mr. edburt, bennet issac
~hooky: (characters) hans wytte, angela wytte, hilde wytte, will's father (ships) mark x dani
~it (2017): pennywise, oscar bowers, alvin marsh
~my hero academia: (characters) minoru mineta, endeavor, overhaul, all for one (ships) bakudeku, kacchako, kirimina, todomomo, kamijirou, izuocha, eijirou kirishima x girls, shota aizawa x women, shota aizawa x ms. joke, eri x anyone
~omori: something
~pjo, hoo, toa: (characters) octavian, nero (ships) lukabeth, perachel, perlypso, romantic meg x apollo
~stranger things: (characters) martin brenner, lonnie byers (ships) stancy, will byers x girls, robin buckley x boys
aesthetics:
-yanderecore
-traumacore
-medicalcore
-religion-based aesthetics (witchy aesthetic is okay, so are holiday-based ones like christmas or halloween {i'll only do holidays when it's close to the date they're happening, though - like,, i won't do samhain at easter, you know?}, but christcore isn't)
other: spiders, blood, corpses
★ ★ ★
may i have a promo, please? thank you!
@electro-kins @primrose-rondo @catte-kins @teabookedits @fairyhimiko @tricky-kins @twisted-lies @lou-edits @cassahina @scftkitti @kinafe @allys-edit-cafe @kin-of-the-sheep @the-local-manga-library + anyone else
feel free to ignore and/or if you don't wanna be tagged, tell me and i'll untag you !!
75 notes
·
View notes
Text

Why I Love Maxine Mayfield’s Storyline (spoilers):
I am a mental health clinician and Max’s storyline really hits home for me, especially this season. It is beautiful, tragic, complicated and powerfully explores important aspects of mental health/illness such as grief, trauma, depression and suicide. I know many people are disappointed that Max still fell victim to Vecna in the final episode of the season, especially after seeing that pivotal and inspiring scene in episode 4, but here’s why I personally understand it (I’m not okay with it because Max is mah GIRL): from a psychological perspective, it makes sense and brings awareness to the people dealing with these mental health concerns on a weekly or daily basis. When we get technical, that moment really represents depression and suicide extremely accurately in that people do manage to fight against their depression and suicidal ideations, but the risk of relapse is completely real (similar to addiction). As many people have already deciphered, Vecna represents depression and suicide; he feeds on his victims’ darkest moments, thoughts and feelings, as well as grief and guilt (or perhaps he, or those thoughts, cause the guilt and grief??). These are risk factors I see everyday when I meet with the kiddos in my office (age range is 5-18). To add to the realistic nature of her “death” in episode 9, she tells Lucas she’s not ready as she is dying in his arms. This is also very realistic and relatable because many suicide survivors (including the ones I have worked with) have reported regretting acting upon their ideations, and have shared feeling most terrified of death in the moment where they thought they’d want it most.

Another important point is that the confusion and disappointment that came after Max’s “death” (which essentially represented a depressive/suicidal relapse) is supposed to happen. Many people who know someone who battles depression often become hurt or confused when they find out that the person in question, who was doing really well for a while, had relapsed back into that depressive state. Some thoughts are “what happened?” “I thought they were doing better?” “But didn’t they overcome that?” These are all logical questions, both in real life and in regards to Max, but the point is that it does sometimes happen. Depression bullies people into believing they are a burden, or that they are guilty of some horrible thing that they realistically had no control over, in Max’s case this being Billy’s death. She shoulders a LOT, if not all of blame for that even when we, as the viewers, know there was nothing she could’ve done; it all happened so fast. She entered the food court where Billy and the Jelly-Mindflayer was and within 3 seconds he had been punched through the abdomen. However, the trauma and grief (much of it being fueled by their indifferent relationship) are running circles in our dear Max, which is leading her to place the guilt on herself, “the shitty little sister”. This does happen and it can be extremely debilitating for those dealing with it (as we saw with her: she was isolating, lost pleasure in fun activities she normally enjoyed, rejected social interactions, her grades were dropping, she was more irritable, was having suicidal thoughts etc.)
As for the push and pull she experienced regarding Billy, that is accurate too because that involves trauma, and trauma is tricky. Many were confused (even angry) that Max shares with Vecna that she experienced dark thoughts about something bad happening to Billy, and that many times she even hoped it would happen. But what about her letter to him in episode 4? I can sympathize with both sides of her dilemma with her step-brother, because, let’s be honest here: Billy was abusive to Max in many ways, was a known racist and made every day hell for her; i.e., driving dangerously with her in the car, pretending like he was going to run over her friends, breaking her skateboard when he found her talking with Lucas, calling her a “little shit” and lord knows what else we didn’t see. As for Billy himself (and as a therapist), I do sympathize with him because given his own difficult and traumatizing backstory, he was made into who he was by his abusive father. Was Billy’s development into that “asshole” understandable? Absolutely, his father can screw off for all I care for ruining what could’ve been a truly wonderful person, but does Billy’s backstory make his actions okay? No. But again, I sympathize and feel truly sorry for him, he didn’t deserve to go through that, but neither did Max. See how complicated is? Max and Billy’s dynamic opens up a conversation about domestic violence, abusive parents, and patterns of abuse sometimes continued on by those who receive it.

Getting back to Max, I understand and respect both sides of Max’s conflict and can’t even begin to understand how confusing it must be to work her head around such contrasting thoughts, where in one breath she sounds like she truly loved her step-brother, but in the next breath saying she hated him.
I could go on and on and on and on about Max’s storyline: her being a tomboy in the 80s, being bullied because of it (but clearly not giving a shit, which I love), moving to a new town in Indiana far away from her Californian father who she clearly missed (S2), losing her new best friend, El, due to her moving away, her whole life getting flipped upside down following Billy’s death, and simply navigating the confusing stage of being a teenager etc., but I’d be here for a week. Just some of my takes on her story and why I appreciate it, especially coming from the mental health field itself. Hoping she’ll pull through in the end, and her fighting spirit, plus her friends, may be enough to save her.
If you read through this whole thing, I appreciate you ❤️❤️❤️
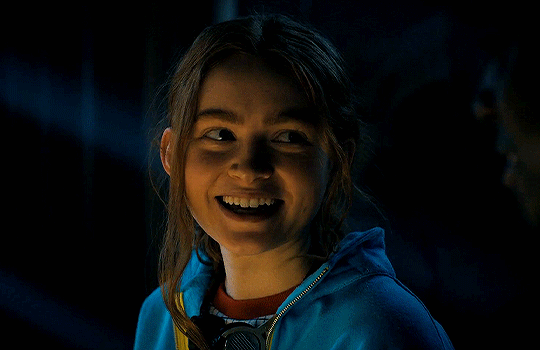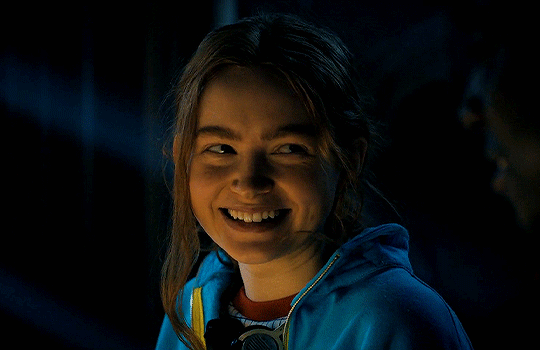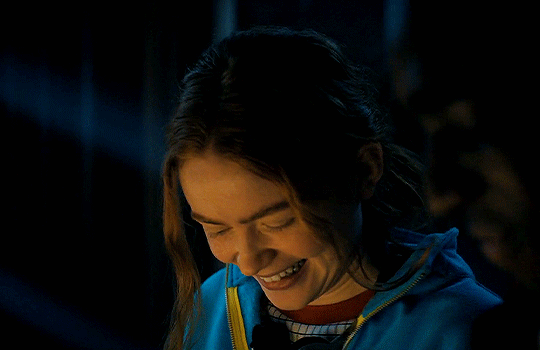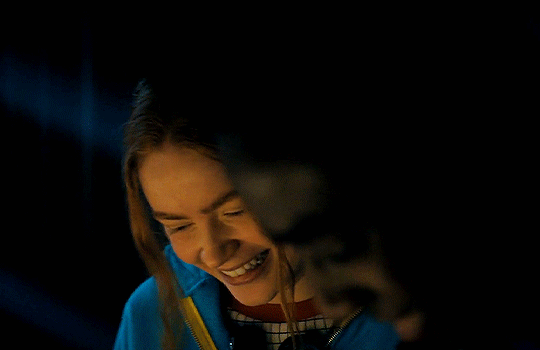

#stranger things#max mayfield#billy hargrove#stranger things 4 vol 2#stranger Things spoilers#ST spoilers#stranger Things 4#Taylor speaks#mental health
15 notes
·
View notes
Text
Not saying you're wrong, because I'm sure this will happen, but it would be a lot funnier if it was Mike doing a self-sacrifice. Think about it, in EVERY SINGLE SEASON Mike has performed at least ONE act of self-sacrificial behavior. Season one? The quarry. Season two? The tunnels (because in case anyone's forgotten it was Mike who convinced everyone to go into the Tunnels just like he did when Will went missing and he convinced Lucas and Dustin to go along with him, because face it he would have gone alone if they said no, to search for Will.) AND him being by Will in general. He knows Will is a spy, he knows Will can hurt him and it would be out of his control, but he still stays for Will's comfort, thus self-sacrifice.
In season 3 he has two major acts of self-sacrifice. Him beating Billy over the head with a pipe for Eleven, and him rushing at Billy after he hurt Max. One he got off with no major injuries, the other he got his face busted in and logically should have scarred so... Season 4 is a bit tricky, if you want to be semantic you could say him pushing Will behind him in that couple of frames by the staircase when they're shooting up the house could be it. However, the entire season could be put in perspective as emotional self-sacrifice. The entire time he's trying to be a better boyfriend for El, he's jealous because he thinks Will is replacing him for some girl but you can see he's also trying to keep his distance, so he doesn't mess things up for Will. After all, boys hugging boys is weird, he doesn't want Will's crush to get the wrong idea. He brought the painting to the airport; Will must really love her that he can't bear to part with it. He decided to give him space in a rush of jealousy. He lied to El to give El what he thought she wanted, despite not wanting it himself. He's sacrificing himself, his wants and needs, for the people he loves.
Now imagine in season 5, everyone knows Will thinks Mike is his heart. And Mike, sacrifices himself for the good of the party, like a true paladin would. So, Will loses his heart, and it hits the general audience harder. I would think Mike would come back but it would be a heart-breaking moment for Will to lose his everything without having got the chance to tell him the truth, the thing Mike values most. it would be very Reddie of them, and just like in IT, everyone picked up that the two loved each other, it would cause the GA to relook everything and cause shockwaves in media has we know it. You really need something BIG to change people's minds, a "I love you" isn't enough because people can go. "Oh Mike was just pressured because that's his best friend and he wants him happy, he likes girls and they'll break up eventually and he'll go back to Eleven, buh, buh, buh." We need something to really shake the ground and a death, even temporary, of either character would do it.
“will is going to sacrifice himsel-” ARE YOU DUMB
166 notes
·
View notes
Text
alright everyone. after my rush of emotions after that season, i’ve had time to decompress, and make an actually cohesive list of my thoughts about the season. as you could probably guess - MAJOR SPOILERS UNDER THE CUT!
first, let’s get the (much) shorter list out of the way. here’s what I enjoyed:
the acting. i want to mention how good millie was, because she was fantastic, but i almost feel like i shouldn’t, bc el took SO MUCH screen and plot time, that millie was given every opportunity to be good. she doesn’t really need any more special mention. otherwise - noah (with the little he was given) and sadie were particularly great. so were winona & david, but that goes without saying.
the elmax friendship. these two deserved it. and max bringing el out of her shell, showing her how to become her own person.... incredible. 10/10 i love them both
alexei. feels weird saying this, but he was probably the new addition I enjoyed watching the most. it would have been kind of cool to see him live past season 3.
an lgbt+ confirmed character. this one is a little.... tricky for me. as happy as I am that there is a queer woman written into the show... I feel like it’s a cop out to not have to confirm will’s sexuality. robin confirms her sexuality in less than a season, but after three with will, we still only get ~subtext~? still, this is a positive portion, so.... I guess that was something I was happy with
el moving in with the byers at the end. finally. this is one of the only things that is keeping me excited for s4. i guess i can only hope for there to FINALLY be some good willel interactions next season, but if this season has taught me anything, it’s not to get my hopes too high :-)
jancy ending s3 on a good note. parts of their storyline were fantastic, some were disappointing. but i really dug their dynamic, and the realistic struggle between the two of them, with nancy not really understanding jonathan’s class struggles, and jonathan not grasping the weight of the misogyny being thrown at nancy. their final moments at the empty byers house at the end were especially lovely.
el no longer being OP, and not being undefeatable. i love el. i really, genuinely do. i love her character, i love her traits, i lover her power. but the duffers were relying too heavily on her to constantly save the day with her powers, and it was happening too often. one of the faults of s2 was the constant thought of how easily el could’ve fought off all these threats if she was just there. i think it’s incredibly interesting to not only see her get completely worn out, but totally lose her powers. like mike said, i’m sure they’ll come back, but i want so badly for el to not just be defined by her powers.
a platonic m/f friendship. yes, one of them is confirmed queer, and they would’ve probably been romantically linked if she was straight. but i’ll take what i can get when it comes to this. platonic opposite sex relationships?? r i s e
now for the meat of my thoughts ~ what I didn’t like:
mike’s characterization. the writers completely made him into a dick this season. i get it, he’s a teenager, so he’s going to be an asshole sometimes. hell, in a recent post, I defended that, saying it’s good writing. but I underestimated just how awful he’d be, completely blowing off his friends for any chance for a second alone with el. I understand that he loves his girlfriend of course, but s1-2 mike loved his friends just as much. he was so utterly unlikable this season, that it seemed like he was a different character.
lucas as comic relief. this is so lazy, and i’m so angry for both the character and caleb, both of whom deserve so much better. he really had nothing to do if it wasn’t related to max, and the writers further reduced him down to a one-dimensional, kind of dumb, mediocre boyfriend, and that is not the highly intelligent, brave, kind lucas that i know and love.
will’s sidelining. god, this made absolutely no sense. noah fucking shined last season. he stole pretty much the entire thing. every critic, even those who disliked the season, had nothing but good things to say about his performance. furthermore, will has so much potential in so many different directions in so many aspects of his character. however, once he revealed to his friends that he was feeling the upside down/MF’s presence... they may as well have written out his character. he was sidelined almost to the point of background character. they gave him very little to do emotionally after that castle byers scene, and even fewer lines.
total lack of willel scenes. phew, if this wasn’t a bummer. will spoke a single line to el, and maybe one or two throwaway lines about her. if there is one thing most of the fans can agree on, it’s that will and el have the biggest connection to the upside down, the biggest unspoken connection, the most parallels, and the most intriguing potential relationship... and they really just said “fuck it” and didn’t have them interact at all. (that’s poor writing folks!) they better make up for this now that they’re living together.
amount of eleven scenes. i love her so dearly. i really do. and i’m so happy she grew into her own, not through mike or hopper. but the amount of el plot and screen time this season was actually difficult to watch. every other scene centered around her. so many characters and so much of the story went undeveloped, while she got way, way more than was necessary. additionally, take any kid’s plot (other than dustin), and guaranteed, it revolved around el. people were starting to catch on that the show was favoring her character more than even most shows’ mains.... and this season took it to a level i actual didn’t think it would.
the comedy. it was so awkwardly written. so much of it threw off the pace of the show. it seemed forced, and just... not very stranger things-esque, where the comedy was typically well-written and blended into dialogue.
the baddies. this was a huge letdown, too. i understand that the monster was large, but it was far less menacing to me than, say, the MF’s physical form. it had gore points, sure. it felt incredibly boring and predictable. in the same vein, i thought the ‘zombie’ style storyline of heather & co. would be deeper than that, but that was literally all it was. again... not interesting to me. billy was a rehash as well. the russians definitely had potential, but even that plot wound up being incredibly one-dimensional.
billy’s screentime. this was one of the things i was absolutely furious about. he got more screentime than the party (minus el) combined. they wanted for us so badly to empathize with him, to humanize him... i’m sorry, but you wrote a character that almost killed a boy for being black, that abuses his sister, and is a misogynistic asshole. abuse doesn’t excuse that, and it’s insulting to abuse survivors to say that billy inevitably became this way because of his dad, and that he deserves our uwus for it... and actually got el’s. he took screen time away from characters who desperately needed it, and that’s something i will never look at the duffers the same way for.
the scoops troop. I wanted to love erica... but i feel so indifferent to her. she was way too much this season. and robin. again, i love that she’s confirmed queer. and i dug her character more. but even then... i don’t know. i would have rather never had her introduced, and allowed established characters to have been better developed. and as a whole, the whole storyline of the troop was just what I feared: underwhelming and awkwardly placed.
high steve & robin. won’t elaborate on this too much, bc there’s not much to elaborate on. it just felt so wildly out of place and unnecessary.
that dustin/suzie number. what the hell was that? what could have been a 20 second joke was stretched out WAY too long and was bizarrely placed. just because you have an actor from broadway, doesn’t mean he needs to sing. and even if he does sing... you couldn’t have found a better time or situation? i literally was just staring at my screen in disbelief as that whole thing happened. entirely unneeded.
the amount of flashbacks. i understand most casual viewers wouldn’t remember certain things because of how long it’s been. but they literally put a recap at the beginning of the season. that’s what it’s for. and there were also plenty from like.... the episode before??? the amount they included took away so much time, that it almost just seemed like they didn’t have enough footage, and they had to fill their time stamp somehow. at some point, it just becomes insulting to the audience’s intelligence.
the overall tone. this season did not feel like stranger things in the slightest. off the top of my head, the castle byers scene and the byeler scene in mike’s garage were the exceptions. the first few episodes did have some moments. but overall... it kind of felt like some weird, high budget commercial or something. the charm, distinct aesthetic, and nuance of seasons 1 and 2 was non-existent.
the post-credit scene. there was some last-minute hype up in the reviews for this. was that supposed to be shocking in some way? i suppose this is more the fault of the reviewers who hyped it, but... really? a demodog? we’ve seen that before... i guess more the point was to show that the russians officially have some kind of technology for this. but still, an underwhelming reveal. more intriguing to me, was if hopper was the american in the cell he mentioned at the start of it. or maybe brenner?
the neutral:
that ending. on one hand, it was incredibly predictable. they literally placed an obvious shot of it in the trailer (easy to deduce that the byers had moved out, and that it was fall, so it was an epilogue scene). i was convinced that there would be a twist element they weren’t showing us, but nope. on the other hand, i thought some things were done beautifully (which wasn’t exactly a trend this season). as i mentioned, i loved the jancy moments. i really did like the hopper voiceover, although it was a little trope-y and heavy-handed... i still got a little emo, ngl. those goodbye hugs were somethin’. and, as i said before... el! moving in! with the byers! gimme
so uh... that’s it, i guess. no one really asked, but i needed to get my thoughts out. what did you guys think of the season?
58 notes
·
View notes
Text
PT Barcelona Report
Shoutouts to Detective Dhaliwal/David Rood for lending me a bunch of cards for the PT, and to Callum Smith for lending me Seasoned Pyromancer on Magic Online. Notes on my modern decklist / choice : I felt with open decklists + london mulligan you had to know your deck inside and out to fully use those systems, you had to know what the mus were about as you had so much agency so I chose UR Phx, I played seasoned pyromancer to work with my leylines vs hoogak so I could mull to 4/5/6 and not die to random bloodghasts which is a real issue as thing/arclight are very weak on very low cards. pryomancer is just very good with leyline. I played gut shot over surgical main because my sb had almost no removal and my deck just wouldn’t sb smoothly without gut shot. plus gut shot is fine vs hoogak stops them convoking and fine in mirrror kills thing. I tried desperate ritual/noxious with aria so I could goldfish turn ¾ vs hoogak but gave up on this cause lazy. I tried dreadhorde arcanist main so I could keep more hands but I found the effect is kinda weak, without open decklists I value cards like flame slash/sinkhole pretty low sine I am mulling to goldfish but with opendecklists I can value these powerful but narrow effects properly, basically like having sb cards main. I played 2 aria main 1 side since I found it is tough to split payoff/enablers, but I felt 3 aria was a bit too much and I would draw aria too much when trying to go off, and it made more hands mulls with the red finale and it being clunky but it was a close call. I also thought about set adrift cause hits hoogak/chalice/aria but My experience in the best with it was not great. I tried titanshift but 0-2d a league vs neoform and mirror, I tried burn but it felt kinda weak to me 3-2d a league lost to uw with timely and rug where they force of negation to blow out my searing blaze on their goyf when I swung with spearo.
I did ~280/300 matches of MH1 Limited in prep for the pt including a trip to GP Seattle where I was granted a nice 12-3 finish (1 bye). I am a newer limited player having only begun really playing it about last year, but since then I have mostly been playing limited as I feel I have a lot more agency in the games and prefer the format. However, since I am relatively new to limited I don’t feel I was able to truly process the amount of information I was receiving as most of what I was learning about in my games, is just what drafting a “master” set is about, and how to handle combat and complex boards in this type of limited environment, so a lot of my attention was drawn away from the actual evaluation of cards and trying to understand how to maximize my value in the game in-game decisions. My plan going into the PT was to soft force black, I wouldn’t just force it if it clearly wasn’t open, but I wouldn’t be shocked if your win rate would be higher taking any black uncommon, or even common over the best green rares and blue mythics p1p1. I found the black decks had so much more synergy and power than the other colors, (I felt the snow decks could trainwreck quite easily and just wasn’t very impressed by springbloom druid) Br and Bu being premium whilst the other black decks were about the same as any other archetype, I wasn’t sure about my read on the format since I am not a limited master and I saw players had different evaluations, but in a practice draft the day before Max Mick agreed this strategy seemed fine, and Malavi/Lars Dam had hit a 2030 elo drafting black every single time. I just found I would win a lot more with black decks and they felt much better, with my previous experience I felt soft forcing black was a reasonable approach. First Draft I get a pretty good BR deck, p1p1 raredraft w6, p1p2 Bogardan Dragonheart p2p3 feaster of fools, black and red cards kept flowing and I didn’t pick up any particular signal except ninjas might be open, pack two I got a pick 4 pashalik mons, but at the end of the draft I probably could have a had a simliar power level ninjas deck but I prefer BR slightly. Round 1 vs Van Vaals, Michael (1966) Michael was in the same Canadian Group chat as me, I was not happy to be paired vs him as in the draft I felt too many good cards were going late and it implied to me the pod mostly consisted of primarily constructed players. Luckily for me he got a bit manascrewed g2 and g3 so I was able to win, he had a BR deck splashing blue for the uncommon ninja and keranos, he also had two hoogaks, indicative of my weekend to come. Round 2 Verdiani, Luca (1869) Versus a UW Flicker deck, not much happened just curved out and stomped. g3 we both mulled to 5, I also played really poorly g2… wake up call for me to not be a doofus. Round 3 Rask, Love (2008) Michael told me there was some insane snow rare deck in the pod his opponent told him about, filled to the brim with rares, I looked at my legion of putrid goblins and they didn’t look too happy, but I trusted in that feaster of fools. My opponent cast a turn 2 bladeback sliver and i’m not feeling afraid anymore, later he curves out hermit druid + dead of winter and I won pretty easily, so I was feeling pretty confident for g3. I had passed a dead of winter in the pod so I messed up a bit g1, it was a bit of a complex line of basically using my Munitions Expert on myself to grow my Scavenger past Dead of Winter, but it could also have backfired in some cases to so it was reasonably hard. After the match my opponent says my deck is insane and his deck is garbage nice.. iirc feels good man. 3-0 Round 4 Maynard, Pascal (1967) Open decklists cool, I see a hoogak deck and look quickly at the manabase and removal spells, g1 Pascal mulls to 5 and I am luckily to kill him on turn 3 or 4 with arclights at 1 life, lucky lucky. G2 my hand was just obscene, looting + 2 arclight + leyline… think there might have even been a force, Pascal just had pretty weak hands so I was able to win. Round 5 Busson, Etienne (2006) Recognized this as the Mono Red player, I was sitting at table 4 and feeling if I win another game or two I could get a feature match maybe so was happy, but wasn’t happy to see this mu. g1 I mulled to 5, game was kinda close, coulda made some slightly different decisions maybe, if I was a bit luckier and hit an extra arclight could have won. g2 turn 1 critter into turn 2 eidolon, coulda maybe ignored the first creature but killed it, interesting choice perhaps, needed to hit an extra arclight or two to win, game was super weird and I tanked the most here, basically opp had an eidolon and I had 2 arclights and I had to decide how to attack and block with the arclights, for example when opp was at 20 life and Iwas at 12 I just attacked with 2 arclights as I felt that was my best chance tow in, was pretty hard, think I made the correct choice, opp agreed game was pretty tricky after. Round 6 Futamata, Yojiro (1798) Open decklists opp is on Hollow Gaak, kinda scared and would prefer a normal Gaak list so I don’t sb poorly or whatever, a bunch of cryptbreakers main and even push. g1 I can’t remember exactly but I think my opp might have mulled once or twice, I had a thing in the ice but opp had push so we move on. g2 I kept with a leyline, opp mulls to 5 I believe, my hand was pretty good, 5 or 6 can’t remember exactly, however as the game progresses I feel I run a bit poorly not being able to trigger arclights or flip my thing for a while, my opp casts a cryptbreaker and just make zombies and I just whiff and whiff but they mulled to 5 and my hand was good so it runs even plus doesn’t matter to my decisions, coulda made some slightly different decisions in relation to fetching to thin which I normally do aggressively, but not sure felt I played fine at worst, in the end I need to dodge either fatal push or bloodghast for one turn to untap and win but opp topdecks the ghast for exactsies feels bad man but feel I played fine. Round 7 Luong, Marcus (2019) Hoogak Dredge, g1 I needed opp to whiff on their last dredge, they had bloodghast conflag and creeping chill as outs, sadly for me they hit and I died. g2 I kept a 5 or 6 with rav trap and the card just sucks vs hoogak so I fire it off a bit early to not get gaaked and die horrible. maybe Rav Trap gamed me as I kept hands assuming it would do stuff and then it just makes me die. Round 8 Nass, Matthew (2015) Table 69, I tell Matt we have the nicest table in the room, I think he agrees. He is also on Gaak, I lose g1 pretty quickly, g2 I keep a hand of like thing + force of negation, maybe was too weak, I tried to bluff I had a leyline by having 1 card I was about to slam in play. Matt keeps a hand with a lot of removal and floods out pretty hard so I am able to win a game I felt I got pretty lucky to win. but idk. g3 I just have 2 leyline + seasoned pyromancer. Feels bad to go 4-0 into 5-3 but I feel I played fine in my losses, didn’t play perfect but I mostly play magic online and find it hard to process information irl and didn’t feel I made too many savage punts. DAY TWO My draft pod has Javier Dominguez, Raph Levy and various other pros. I am sitting next to vidi, p1p1 I take urza over mob mostly due to being 50$, p1p2 I slam a manowar, rp1p3 there is goblin war party lightning skelelemental and ninja removal spell entwine. I think wow br seems open. I remember the lr advice, I can take one of these nut br cards and get passed an a+ br deck potentially or stay on ninjas and get a maybe b ish deck on average. I took skelelemental but some of my friends who are better said first of all there aren’t many rare blue cards better than manowar so manowar is a light blue signal, second of all they said skelemental isn’t that good and they said thirdly the two blue cards are too good so they’d try really hard to play it. Might have messed up my draft as RB was very very not open, I continued taking UB cards but Vidi was also in UB, p2p1 I took a fallen shinobi and didn’t feel black was being cut til mid pack 2 but was too late then, still I feltmy deck could win games. Round 9 Wijaya, Vidianto (2013) We play a Ninja Mirror, I just wait til he taps out both games and use fallen shinobi, I accidentally stole one of his lands and when I return it to him later he says fucking fallen shinobi. Round 10 Levy, Raphael (2112) g1 was pretty close, I had a choking tethers and every turn just needed him to have 1 less spell to get lethal, he had a marit lage enchantment and kept playing snow lands every turn, I Had 2 strings so I wasn’t too scared but cascade sliver + lots of removal was enough to kill me in a close game. g2 I had 18 lands due to 3 cycling ones, I side out a talisman for a spell snuff since talisman is in my deck to ramp into cards liek pondering mage/urza/first sphere/other nonsense vs more aggresive decks where I need to get on the board, here I want to be aggresive but those cards aren’t that aggresive and I felt spell snuff would be good. I keep a 2 lander with choking tethers as the hand is just good with an urza in it but sadly I get stuck on 2 lands and draw both spell snuffs, i’d sb the same again but felt kinda bad. Round 11 Matsumoto, Yuki (2000) vs BR, g1 my opp casts a silumar scavenger I spell snuff and untap, my board is urza + 5/6 lands with talisman and 2/2 token, my opp has like 4ish cards in hand and board of changelign outcast + bladeback sliver + 5 lands, my hand is like fallen shinobi + strings, can’t remember exactly what else I had in hand, I believe I also might have had a preordain in my graveyard. My deck doesn’t have much removal really outside of 2 strings and choking tethers so I try to be aggresive and close game quickly, I bounce the bladeback with strings and fallen shinobi the urza, Ken Yukihiro sitting next to us laughs,I hit a land and volatile claws *fuck* and pass. opp hardcasts an igneous elemental killing my 2/2 token, I can’t attack with shinobi so I cast urza and pass, they now goatnap shinobi I chump with token they cast dragonheart and suddenly i’m way far behind and feeling terrible, I feel I prob messed up this game somewhere, I just saw an insane line and went for it, coulda thought more but honestly likely would have came to same conclusion, g2 is pretty close but pretty much my opp casts a bunch of big creatures and removal and I die since my deck is just very medium and leaning on fallen shinobi or smoke shroud to win. Feeling pretty bad since my winrate in MH draft is muuuuchh higher than modern but I felt I just need to learn more for next time, feels bad but here we are. I felt my choices were mostly reasonable even if they might not have been the best I tried. Round 12 Vorel, Andrew (1847) VS Hoogak, can’t remember much, just leyline g2 and g3. puts me to 3-2 vs hoogak and I was doing well vs it on modo idk close mu. feels good to win Round 13 Jones, Derrick (1817) Izzet Phoenix Mirror, g1 I go turn 2 thought scour myself mill phx I scried on top, gut shot + bolt your thing in the ice and end up winning by goldfishing better I suppose. g2 my opp has to surgical random things to protect his thing from my flame slash but I am able to have a nuttier hand and win. feels good to be winning in modern atleast today. Round 14 Prosek, Dominik (1969) We get into a disagreement late into g2 whether a card was in my hand or graveyard, I believe I went to cast bolt and grab dice for aria and when I looked again my bolt was in my graveyard and I didn’t say I cast it, but it is possible I just messed up somehow, we end up with like 7 judge calls and with diminishing time extensions get a draw in a g3 I felt very far ahead in (two arias on 5 on turn 5 of time) but opp didn’t slowplay as they also believed they would have won close game, my first really fun game of teh weekend as g2 and g3 were just extremely grindy both players slamming haymakers, mostly said my favorite cause I was just winning a long game. Round 15 Wijaya, Vidianto (2005) I get pretty lucky and win a PHX mirror, I make a small misplay maybe g1, drew my 1 of rav trap g2 and draw pretty nutty, but that’s what I signed up for. Round 16 Stihle, Julien (2008) For 750$, I didn’t know at the time but I sure did after, g1 and g3 I mull to 5 vs UW, still kinda close, feels pretty bad wish I would have shuffled more idk, think I played the games fine,g2 felt pretty good though as I get to use the gy ability of two seasoned pyros and win a drawn out game. kinda bummed at myself for getting a draw in round 14, but I think I played fine, got slightly sloppy when time approached but that is fine by me considering the circumstances, I shouldn’t have spammed the judge calls so much but I don’t play much irl so I learned my lesson. a painful one. also I felt kinda dumb about the second draft but I still liked my decisions based on my previous experience even if I got a 1-2 record. happy with 9-6-1, felt I played ok but I feel next time if I can queue I will be able to focus a lot more. PT was overall more fun than I expected, the venue was a lot nicer than a GP one, you also get to spend a lot of time around die hard mtg players whereas at a GP I feel more like an outcast since I play way too much mtg, here I felt most players also do so. You get lots of cool stuff and etc. Also drafting is fun and you don’t even need to day 2 sealed to do so.
2 notes
·
View notes
Note
I'm sorry the Billy stans keep on harassing you on here, it totally sucks because you made some valid points in terms of how people react towards real life serial killers or abusers when they are attractive (i.e Dahmer and to some extent Johnny Depp and now Bratt Pitt) and how this mirrors the ractions to hot abusive fictional characters.
A large problem why we are even having the racism question for Billy is due to Dacre's comments about him not wanting to play Billy as racist, demanding the Duffers to cut out the slurs he was supposed to say. However, that doesn't change the fact that Billy's actions inherently were racist tho, but people have a hard time acknowledging it when it's not spelled out for them. It's also problematic how they ignore Caleb's view or the literal creators and only focus on the white actor who played his character's actions down. If you can't handle playing a racist character you shouldn't have played the character in the first place.
Personally I would consider myself as a Billy neutral, I don't particularly care about him. Obviously I hate his treatment of Max and Lucas and I definitely acknowledged as what it was, abuse and racism. However I can kinda understand where he is coming from and some of his stans, those who are genuinely not excusing his actions, have made some interesting points about how his abuse from his dad made his character the way he is and I feel like acknowledging this side while still condemning Billy's behavior towards other characters is a good way to deal with his character in my opinion. There are also a bunch of people who are relating to him in terms of how Billy reacts to his abuse, including black people and other marginalized groups, and I feel like it's a bit harsh to fully condemn them by saying oh they are wrong and don't know what they are talking about. I also understand them wanting to have a redemption arc or wanting to explore how his character could change if removed from the abuser like Jonathan was removed from the abuse. That's why I don't like comparing those two characters because while enduring similar stuff, Jonathan had a support system and was free of his dad while Billy still was constantly under his thumb. Many people I spoke to or saw posts who relate to Billy were like him at some point but were able to change so that's what they project onto him, again I don't see anything wrong with that but I do have problems with people who sweep every bad thing he did under a rug. It's a tricky situation I guess because who am I to police abuse victims on how they can relate to certain characters or not.
I'm sorry if this is a bit all over the place but for me Billy is a complicated character to discuss as there are valid points on both sides but also way too extreme reactions from antis and stans alike. Bottom line is Billy was a racist and abusive, and that shouldn't be excused from either side.
don't apologize anon, thank you for your kindness
thank you for talking about johnny depp and brad pitt bc i was clearly referring to them (and others) with my post. the way people only listen to dacre's point of view and not caleb's shows what structural racism is. no hate to dacre, he is just an actor and i don't blame him but at least he could have accepted billy's racism. i'm aware it is not easy to break the cycle of abuse when we grow up in abusive households. i'm not trying to invalidate what happened to him but as you said it doesn't excuse his racism and misogyny. i'm not against tv shows potraying these type of characters bc they exist, i'm against fetishizing abusive men because even though billy is fictional, this happens in real life too, all the time.
keep sending asks i really like recieving them and love debating
1 note
·
View note
Text
what i'm saying right?! asdfasjdf it's such an unfortunate coincidence for them too
because Mike and Dustin wear their hellfire shirts openly on display the entire day and we get a whole montage dedicated to them poking their head into every single club in school "recruiting" for Hellfire. like... well that's surely not a bad look
so even aside from Dustin, Lucas, and Mike being on every single one of the Hellfire wanted posters, Mike and Dustin went to tell everyone they're members themselves. and on the same day Chrissy died too!
and since she then dies in Eddie's trailer the logical assumptions as a student that only knows this and that Jason claimed Hellfire does ritualistic sacrifices right before he died/went missing? i would for sure remember the weird kid coming in on the day of the first murder asking if i wanted to "join a game, only once tho, i swear it's fun"
at this point i don't even know who looks the worst out of the three
like, Mike leaving town probably looks Really bad. at least for Chrissy's murder. also kinda tricky since as a townsperson believing in a cult you could probably also just assume it's an alibi and that he didn't leave town at all. he also visually looks similar to Eddie and wears the hellfire shirt the most prominent since he has nothing over it
then Dustin gets specifically picked out on by the basketball team already. but at least no one in the town knows how close he actually was with Eddie specifically, however, him hanging around with Eddie's uncle is probably a horrible look too
and Lucas is already seen as a traitor by the basketball team and has the potential to look even Worse if someone made the connection that he was with Max when she died or if they would have found remains of Jason in the room with him. but no one knows that hopefully
it's really so bad for all of them. Jason setting the whole town on Hellfire right before he died still had 0 consequences in canon. nada. it was only the basketball team that was hostile in s4. so whatever the consequences will be, it'll probably not be fun for the three
Joyce staying at the cabin with Hopper and El to keep them safe bc no one in Hawkins knows they’re alive. Will, Jonathan and Argyle staying at the Wheeler's bc they have more room and presumably aren't in danger like the others.
OH WAIT there's a witch hunt for the Hellfire club, which means all the boys are in danger from the townspeople. OH WAIT the boy who came back to life has returned from the West, the same boy whose assumed death jumpstarted this small town's curse in the first place! The same boy who apparently everyone and their fathers knew was gay...
THE END IS NEAR! THE GAYS ARE RESPONSIBLE!
+ Time jump early somewhere in between.
Now picture how that would look in an 8 episode story format, leading up to a final battle lasting about 2+ hrs, and that's loosely how s5 is gonna go down.
#the Mike and Dustin montage is so incriminating in universe#like it's not even funny#they have club t shirts on and start asking for subs the day someone goes to their club leaders trailer and gets killed?#funny coincidence for sure#akjhsfa
507 notes
·
View notes
Text
The Moment Paris-Nice Was Won

In 1972 Eddy Merckx was so confident of winning Paris-Nice that before the start of the final stage he posed for photos with a speedboat, a prize that year. Only Raymond Poulidor rocketed up the Col d’Eze to win the stage, take the race overall and collect the prize. Primož Roglič can show a cannibal-like trait at times but must also know a thing or two about not counting chickens until they hatch, or as they say in Slovenian, “not praising the day until the evening”. But on the morning of the final stage it did look like Roglič had Paris-Nice sewn up and he even had a good chance of winning the final stage too…
Many star riders had opted for Tirreno-Adriatico, but if two simultaneous World Tour races might sound incongruous to outsiders or management consultants, the format works well with a large share of the peloton able to bank a week-long stage race in mid-March and views able getting double the action. Perhaps more than Wout van Aert or Julian Alaphilippe, the one thing Paris-Nice really missed this year was the wind. Ride from Paris to Nice and long days across the plains are inevitable, and if the weather is benign, so is the racing.

We got some fine bunch sprints, but this is the sporting version of nouvelle cuisine when we’d hoped for a feast, a daily dish to be consumed in seconds rather than hours. Sam Bennett won the opening stage in Saint Cyr and would take second while Cees Bol seized the moment to take a chaotic finish, too.
Without echelons on the first two days, the time trial in Gien was the first obvious rendez-vous for the GC contenders and Roglič was the best, just behind Stefan Bissegger and Rémi Cavagna, with Brandon McNulty close, then Max Schachmann and Sacha Vlasov close by. The likes of Tao Geoghegan Hart, Jai Hindley, David Gaudu and Guillaume Martin were among those on the receiving end in a 14km time trial and they’ll face four times this distance if they ride the Tour de France.

The wine stage past Macon and into the Beaujolais was a lively one with a difficult finishing circuit. These are not legendary roads but they do offer great riding for visitors and make just as good terrain for racing as they do red wine. All talk of wine tasting was spat out with Roglič’s late surge to win solo as he crushed his rivals like they were grapes in a vat. He took 12 seconds by the line and another 13 in time bonuses with Schachmann again close by, and this was the German once again the second best. Schachmann finished 19th on the stage to Biot won by Roglič, but all were on the same time so this momentary gap didn’t cost anything.
Schachmann was back on Roglič’s wheel for the big mountain top finish to La Colmiane. Gino Mäder was the lone breakaway survivor and with a chance of the stage win, but after everyone else was dropped Roglič launched one last time to shake off Schachi and got clear, rounded Mäder and took the stage win, his third so far. Some would have preferred if he could have let Mäder win, but this was no place for gifts with Roglič being hounded by Schachmann, who’d been right on his wheel and still seconds separating the main riders on GC with a tricky stage behind Nice still to come, rather. We don’t need hindsight to see Roglič couldn’t afford to play Santa either. Name a rider who has lost a stage race because they didn’t distance their rivals enough: Roglič. Name a rider who has seen stage races slip from him on the last day: Roglič. He’d be a tragic figure if it wasn’t for all the races he wins.
The final stage of Paris-Nice is never a victory parade. Ever since the Col d’Eze time trial was abolished it’s often the most difficult and spectacular day of the week. Still, the briefing on the Jumbo team bus wouldn’t have lasted long, a stage on the same roads as last summer’s Tour de France and within easy riding of several of the squad’s Monaco apartments presented few surprises and they needed to keep a lid on the race so that Schachmann and Astana didn’t take time; maybe letting a breakaway go to mop up the time bonuses would help. “Just keeping Primož safe to bring it home“.

Which brings us to the moment the race was lost. Or rather the moments, because like many disasters, it’s not one mishap but a chain of events. The first crash on the descent from Levens to Roquette – the same used in the Tour de France’s opening stage last year, the ice-rink stage – where he dislocated his shoulder and had his shorts shredded. Many would demand days off work following an accident like this, yet Roglič was back on the bike but, however quickly we see a rider remount, these incidents are never cost-free. Muscles ache, skin burns, adrenalin has burned up energy reserves, swelling starts and more. Then Roglič crashed again on the same descent the next time and jammed his chain. He got a replacement bike but had to chase and there was a barrage, where the convoy was being held back, leaving Roglič and his Jumbo-Visma teammates to close the gap. They’re strong, but lacked a big rouleur and the likes of Oomen, Kruijswijk and Bennett were spent quickly in the chase up the Vésubie valley, leaving Roglič alone to close the final gap of less than ten seconds. This was the point of maximum danger, where the final metres are often the hardest part of the gap to close, and meanwhile, Astana and Bora-Hansgrohe had riders on the front, so it was a lone rider in yellow versus a team trial.
Roglič never gave up though, climbing as fast as he could and prompting many double takes from dropped riders coasting up the last climb and upon reaching the finish, congratulated Schachmann on his win with a fist-bump when by all accounts he might have felt like something less gracious and would be entitled to vanish inside the team bus right away (he didn’t show up for the podium ceremony to collect the points jersey). Schachmann himself said he didn’t want to win this way but he did, and not just because Roglič crashed, but because someone else had to win and all throughout he was the second best rider. It’s a small consolation for last year’s winner on his way back after that accident in Bergamo that broke his collarbone.

The Verdict Not a vintage edition because the wind didn’t enliven the opening stages and once the race reached hillier terrain, the GC battle wasn’t much of a contest either. But like a restaurant that served up a surprise dessert, the memory might be of the final dish in the hills behind Nice. Primož Roglič looked to have the race sewn up with two stage wins and being the best-placed GC rider from the time trial, but all this just left him seconds ahead of his rivals and one crash was enough to topple him from the podium. He wasn’t alone: Richie Porte, Tao Geoghegan Hart and Brandon McNulty would also crash out of the race, and the absence of Ineos’s leaders allowed Jumbo-Visma to keep a grip on the race all week, but the final stage twist just adds to the lore of Paris-Nice.
Paris-Nice is often a small dress rehearsal for the Tour. Younger riders get a go and the youth competition showed strong rides by Vlasov, Lucas Hamilton, Jorgensen, McNulty and Paret-Peintre. It’s a tune up for next weekend’s Milan-Sanremo, too. But perhaps the long term effect will be on Jumbo-Visma; the team will give leadership to some of their other riders in upcoming stage races but last week’s racing suggests they’ll play it even safer in July.
The Moment Paris-Nice Was Won published first on https://motocrossnationweb.weebly.com/
0 notes
Text
The Data You’re Using to Calculate CTR is Wrong and Here’s Why
Posted by Luca-Bares
Click Through Rate (CTR) is an important metric that’s useful for making a lot of calculations about your site’s SEO performance, from estimating revenue opportunity, prioritize keyword optimization, to the impact of SERP changes within the market. Most SEOs know the value of creating custom CTR curves for their sites to make those projections more accurate. The only problem with custom CTR curves from Google Search Console (GSC) data is that GSC is known to be a flawed tool that can give out inaccurate data. This convolutes the data we get from GSC and can make it difficult to accurately interpret the CTR curves we create from this tool. Fortunately, there are ways to help control for these inaccuracies so you get a much clearer picture of what your data says.
By carefully cleaning your data and thoughtfully implementing an analysis methodology, you can calculate CTR for your site much more accurately using 4 basic steps:
Extract your sites keyword data from GSC — the more data you can get, the better.
Remove biased keywords — Branded search terms can throw off your CTR curves so they should be removed.
Find the optimal impression level for your data set — Google samples data at low impression levels so it’s important to remove keywords that Google may be inaccurately reporting at these lower levels.
Choose your rank position methodology — No data set is perfect, so you may want to change your rank classification methodology depending on the size of your keyword set.
Let’s take a quick step back
Before getting into the nitty gritty of calculating CTR curves, it’s useful to briefly cover the simplest way to calculate CTR since we’ll still be using this principle.
To calculate CTR, download the keywords your site ranks for with click, impression, and position data. Then take the sum of clicks divided by the sum of impressions at each rank level from GSC data you’ll come out with a custom CTR curve. For more detail on actually crunching the numbers for CTR curves, you can check out this article by SEER if you’re not familiar with the process.
Where this calculation gets tricky is when you start to try to control for the bias that inherently comes with CTR data. However, even though we know it gives bad data we don’t really have many other options, so our only option is to try to eliminate as much bias as possible in our data set and be aware of some of the problems that come from using that data.
Without controlling and manipulating the data that comes from GSC, you can get results that seem illogical. For instance, you may find your curves show position 2 and 3 CTR’s having wildly larger averages than position 1. If you don’t know that data that you’re using from Search Console is flawed you might accept that data as truth and a) try to come up with hypotheses as to why the CTR curves look that way based on incorrect data, and b) create inaccurate estimates and projections based on those CTR curves.
Step 1: Pull your data
The first part of any analysis is actually pulling the data. This data ultimately comes from GSC, but there are many platforms that you can pull this data from that are better than GSC's web extraction.
Google Search Console — The easiest platform to get the data from is from GSC itself. You can go into GSC and pull all your keyword data for the last three months. Google will automatically download a csv. file for you. The downside to this method is that GSC only exports 1,000 keywords at a time making your data size much too small for analysis. You can try to get around this by using the keyword filter for the head terms that you rank for and downloading multiple 1k files to get more data, but this process is an arduous one. Besides the other methods listed below are better and easier.
Google Data Studio — For any non-programmer looking for an easy way to get much more data from Search Console for free, this is definitely your best option. Google Data Studio connects directly to your GSC account data, but there are no limitations on the data size you can pull. For the same three month period trying to pull data from GSC where I would get 1k keywords (the max in GSC), Data Studio would give me back 200k keywords!
Google Search Console API — This takes some programming know-how, but one of the best ways to get the data you’re looking for is to connect directly to the source using their API. You’ll have much more control over the data you’re pulling and get a fairly large data set. The main setback here is you need to have the programming knowledge or resources to do so.
Keylime SEO Toolbox — If you don’t know how to program but still want access to Google’s impression and click data, then this is a great option to consider. Keylime stores historical Search Console data directly from the Search Console API so it’s as good (if not better) of an option than directly connecting to the API. It does cost $49/mo, but that’s pretty affordable considering the value of the data you’re getting.
The reason it’s important what platform you get your data from is that each one listed gives out different amounts of data. I’ve listed them here in the order of which tool gives the most data from least to most. Using GSC’s UI directly gives by far the least data, while Keylime can connect to GSC and Google Analytics to combine data to actually give you more information than the Search Console API would give you. This is good because whenever you can get more data, the more likely that the CTR averages you’re going to make for your site are going to be accurate.
Step 2: Remove keyword bias
Once you’ve pulled the data, you have to clean it. Because this data ultimately comes from Search Console we have to make sure we clean the data as best we can.
Remove branded search & knowledge graph keywords
When you create general CTR curves for non-branded search it’s important to remove all branded keywords from your data. These keywords should have high CTR’s which will throw off the averages of your non-branded searches which is why they should be removed. In addition, if you’re aware of any SERP features like knowledge graph you rank for consistently, you should try to remove those as well since we’re only calculating CTR for positions 1–10 and SERP feature keywords could throw off your averages.
Step 3: Find the optimal impression level in GSC for your data
The largest bias from Search Console data appears to come from data with low search impressions which is the data we need to try and remove. It’s not surprising that Google doesn’t accurately report low impression data since we know that Google doesn’t even include data with very low searches in GSC. For some reason Google decides to drastically over report CTR for these low impression terms. As an example, here’s an impression distribution graph I made with data from GSC for keywords that have only 1 impression and the CTR for every position.
If that doesn’t make a lot of sense to you, I’m right there with you. This graph says a majority of the keywords with only one impression has 100 percent CTR. It’s extremely unlikely, no matter how good your site’s CTR is, that one impression keywords are going to get a majority of 100 percent CTR. This is especially true for keywords that rank below #1. This gives us pretty solid evidence low impression data is not to be trusted, and we should limit the number of keywords in our data with low impressions.
Step 3 a): Use normal curves to help calculate CTR
For more evidence of Google giving us biased data we can look at the distribution of CTR for all the keywords in our data set. Since we’re calculating CTR averages, the data should adhere to a Normal Bell Curve. In most cases CTR curves from GSC are highly skewed to the left with long tails which again indicates that Google reports very high CTR at low impression volumes.
If we change the minimum number of impressions for the keyword sets that we’re analyzing we end up getting closer and closer to the center of the graph. Here’s an example, below is the distribution of a site CTR in CTR increments of .001.
The graph above shows the impressions at a very low impression level, around 25 impressions. The distribution of data is mostly on the right side of this graph with a small, high concentration on the left implies that this site has a very high click-through rate. However, by increasing the impression filter to 5,000 impressions per keyword the distribution of keywords gets much much closer to the center.
This graph most likely would never be centered around 50% CTR because that’d be a very high average CTR to have, so the graph should be skewed to the left. The main issue is we don’t know how much because Google gives us sampled data. The best we can do is guess. But this raises the question, what’s the right impression level to filter my keywords out to get rid of faulty data?
One way to find the right impression level to create CTR curves is to use the above method to get a feel for when your CTR distribution is getting close to a normal distribution. A Normally Distributed set of CTR data has fewer outliers and is less likely to have a high number of misreported pieces of data from Google.
3 b): Finding the best impression level to calculate CTR for your site
You can also create impression tiers to see where there’s less variability in the data you're analyzing instead of Normal Curves. The less variability in your estimates, the closer you’re getting to an accurate CTR curve.
Tiered CTR tables
Creating tiered CTR needs to be done for every site because the sampling from GSC for every site is different depending on the keywords you rank for. I’ve seen CTR curves vary as much as 30 percent without the proper controls added to CTR estimates. This step is important because using all of the data points in your CTR calculation can wildly offset your results. And using too few data points gives you too small of a sample size to get an accurate idea of what your CTR actually is. The key is to find that happy medium between the two.
In the tiered table above, there’s huge variability from All Impressions to >250 impressions. After that point though, the change per tier is fairly small. Greater than 750 impressions are the right level for this site because the variability among curves is fairly small as we increase impression levels in the other tiers and >750 impressions still gives us plenty of keywords in each ranking level of our data set.
When creating tiered CTR curves, it’s important to also count how much data is used to build each data point throughout the tiers. For smaller sites, you may find that you don’t have enough data to reliably calculate CTR curves, but that won’t be apparent from just looking at your tiered curves. So knowing the size of your data at each stage is important when deciding what impression level is the most accurate for your site.
Step 4: Decide which position methodology to analyze your data
Once you’ve figured out the correct impression-level you want to filter your data by you can start actually calculating CTR curves using impression, click, and position data. The problem with position data is that it’s often inaccurate, so if you have great keyword tracking it’s far better to use the data from your own tracking numbers than Google’s. Most people can’t track that many keyword positions so it’s necessary to use Google’s position data. That’s certainly possible, but it’s important to be careful with how we use their data.
How to use GSC position
One question that may come up when calculating CTR curves using GSC average positions is whether to use rounded positions or exact positions (i.e. only positions from GSC that rank exactly 1. So, ranks 1.0 or 2.0 are exact positions instead of 1.3 or 2.1 for example).
Exact position vs. rounded position
The reasoning behind using exact position is we want data that’s most likely to have been ranking in position 1 for the time period we’re measuring. Using exact position will give us the best idea of what CTR is at position 1. Exact rank keywords are more likely to have been ranking in that position for the duration of the time period you pulled keywords from. The problem is that Average Rank is an average so there’s no way to know if a keyword has ranked solidly in one place for a full time period or the average just happens to show an exact rank.
Fortunately, if we compare exact position CTR vs rounded position CTR, they’re directionally similar in terms of actual CTR estimations with enough data. The problem is that exact position can be volatile when you don’t have enough data. By using rounded positions we get much more data, so it makes sense to use rounded position when not enough data is available for exact position.
The one caveat is for position 1 CTR estimates. For every other position average rankings can pull up on a keywords average ranking position and at the same time they can pull down the average. Meaning that if a keyword has an average ranking of 3. It could have ranked #1 and #5 at some point and the average was 3. However, for #1 ranks, the average can only be brought down which means that the CTR for a keyword is always going to be reported lower than reality if you use rounded position.
A rank position hybrid: Adjusted exact position
So if you have enough data, only use exact position for position 1. For smaller sites, you can use adjusted exact position. Since Google gives averages up to two decimal points, one way to get more “exact position” #1s is to include all keywords which rank below position 1.1. I find this gets a couple hundred extra keywords which makes my data more reliable.
And this also shouldn’t pull down our average much at all, since GSC is somewhat inaccurate with how it reports Average Ranking. At Wayfair, we use STAT as our keyword rank tracking tool and after comparing the difference between GSC average rankings with average rankings from STAT the rankings near #1 position are close, but not 100 percent accurate. Once you start going farther down in rankings the difference between STAT and GSC become larger, so watch out how far down in the rankings you go to include more keywords in your data set.
I’ve done this analysis for all the rankings tracked on Wayfair and I found the lower the position, the less closely rankings matched between the two tools. So Google isn’t giving great rankings data, but it’s close enough near the #1 position, that I’m comfortable using adjusted exact position to increase my data set without worrying about sacrificing data quality within reason.
Conclusion
GSC is an imperfect tool, but it gives SEOs the best information we have to understand an individual site's click performance in the SERPs. Since we know that GSC is going to throw us a few curveballs with the data it provides its important to control as many pieces of that data as possible. The main ways to do so is to choose your ideal data extraction source, get rid of low impression keywords, and use the right rank rounding methods. If you do all of these things you’re much more likely to get more accurate, consistent CTR curves on your own site.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes
Text
The Data You’re Using to Calculate CTR is Wrong and Here’s Why
Posted by Luca-Bares
Click Through Rate (CTR) is an important metric that’s useful for making a lot of calculations about your site’s SEO performance, from estimating revenue opportunity, prioritize keyword optimization, to the impact of SERP changes within the market. Most SEOs know the value of creating custom CTR curves for their sites to make those projections more accurate. The only problem with custom CTR curves from Google Search Console (GSC) data is that GSC is known to be a flawed tool that can give out inaccurate data. This convolutes the data we get from GSC and can make it difficult to accurately interpret the CTR curves we create from this tool. Fortunately, there are ways to help control for these inaccuracies so you get a much clearer picture of what your data says.
By carefully cleaning your data and thoughtfully implementing an analysis methodology, you can calculate CTR for your site much more accurately using 4 basic steps:
Extract your sites keyword data from GSC — the more data you can get, the better.
Remove biased keywords — Branded search terms can throw off your CTR curves so they should be removed.
Find the optimal impression level for your data set — Google samples data at low impression levels so it’s important to remove keywords that Google may be inaccurately reporting at these lower levels.
Choose your rank position methodology — No data set is perfect, so you may want to change your rank classification methodology depending on the size of your keyword set.
Let’s take a quick step back
Before getting into the nitty gritty of calculating CTR curves, it’s useful to briefly cover the simplest way to calculate CTR since we’ll still be using this principle.
To calculate CTR, download the keywords your site ranks for with click, impression, and position data. Then take the sum of clicks divided by the sum of impressions at each rank level from GSC data you’ll come out with a custom CTR curve. For more detail on actually crunching the numbers for CTR curves, you can check out this article by SEER if you’re not familiar with the process.
Where this calculation gets tricky is when you start to try to control for the bias that inherently comes with CTR data. However, even though we know it gives bad data we don’t really have many other options, so our only option is to try to eliminate as much bias as possible in our data set and be aware of some of the problems that come from using that data.
Without controlling and manipulating the data that comes from GSC, you can get results that seem illogical. For instance, you may find your curves show position 2 and 3 CTR’s having wildly larger averages than position 1. If you don’t know that data that you’re using from Search Console is flawed you might accept that data as truth and a) try to come up with hypotheses as to why the CTR curves look that way based on incorrect data, and b) create inaccurate estimates and projections based on those CTR curves.
Step 1: Pull your data
The first part of any analysis is actually pulling the data. This data ultimately comes from GSC, but there are many platforms that you can pull this data from that are better than GSC's web extraction.
Google Search Console — The easiest platform to get the data from is from GSC itself. You can go into GSC and pull all your keyword data for the last three months. Google will automatically download a csv. file for you. The downside to this method is that GSC only exports 1,000 keywords at a time making your data size much too small for analysis. You can try to get around this by using the keyword filter for the head terms that you rank for and downloading multiple 1k files to get more data, but this process is an arduous one. Besides the other methods listed below are better and easier.
Google Data Studio — For any non-programmer looking for an easy way to get much more data from Search Console for free, this is definitely your best option. Google Data Studio connects directly to your GSC account data, but there are no limitations on the data size you can pull. For the same three month period trying to pull data from GSC where I would get 1k keywords (the max in GSC), Data Studio would give me back 200k keywords!
Google Search Console API — This takes some programming know-how, but one of the best ways to get the data you’re looking for is to connect directly to the source using their API. You’ll have much more control over the data you’re pulling and get a fairly large data set. The main setback here is you need to have the programming knowledge or resources to do so.
Keylime SEO Toolbox — If you don’t know how to program but still want access to Google’s impression and click data, then this is a great option to consider. Keylime stores historical Search Console data directly from the Search Console API so it’s as good (if not better) of an option than directly connecting to the API. It does cost $49/mo, but that’s pretty affordable considering the value of the data you’re getting.
The reason it’s important what platform you get your data from is that each one listed gives out different amounts of data. I’ve listed them here in the order of which tool gives the most data from least to most. Using GSC’s UI directly gives by far the least data, while Keylime can connect to GSC and Google Analytics to combine data to actually give you more information than the Search Console API would give you. This is good because whenever you can get more data, the more likely that the CTR averages you’re going to make for your site are going to be accurate.
Step 2: Remove keyword bias
Once you’ve pulled the data, you have to clean it. Because this data ultimately comes from Search Console we have to make sure we clean the data as best we can.
Remove branded search & knowledge graph keywords
When you create general CTR curves for non-branded search it’s important to remove all branded keywords from your data. These keywords should have high CTR’s which will throw off the averages of your non-branded searches which is why they should be removed. In addition, if you’re aware of any SERP features like knowledge graph you rank for consistently, you should try to remove those as well since we’re only calculating CTR for positions 1–10 and SERP feature keywords could throw off your averages.
Step 3: Find the optimal impression level in GSC for your data
The largest bias from Search Console data appears to come from data with low search impressions which is the data we need to try and remove. It’s not surprising that Google doesn’t accurately report low impression data since we know that Google doesn’t even include data with very low searches in GSC. For some reason Google decides to drastically over report CTR for these low impression terms. As an example, here’s an impression distribution graph I made with data from GSC for keywords that have only 1 impression and the CTR for every position.
If that doesn’t make a lot of sense to you, I’m right there with you. This graph says a majority of the keywords with only one impression has 100 percent CTR. It’s extremely unlikely, no matter how good your site’s CTR is, that one impression keywords are going to get a majority of 100 percent CTR. This is especially true for keywords that rank below #1. This gives us pretty solid evidence low impression data is not to be trusted, and we should limit the number of keywords in our data with low impressions.
Step 3 a): Use normal curves to help calculate CTR
For more evidence of Google giving us biased data we can look at the distribution of CTR for all the keywords in our data set. Since we’re calculating CTR averages, the data should adhere to a Normal Bell Curve. In most cases CTR curves from GSC are highly skewed to the left with long tails which again indicates that Google reports very high CTR at low impression volumes.
If we change the minimum number of impressions for the keyword sets that we’re analyzing we end up getting closer and closer to the center of the graph. Here’s an example, below is the distribution of a site CTR in CTR increments of .001.
The graph above shows the impressions at a very low impression level, around 25 impressions. The distribution of data is mostly on the right side of this graph with a small, high concentration on the left implies that this site has a very high click-through rate. However, by increasing the impression filter to 5,000 impressions per keyword the distribution of keywords gets much much closer to the center.
This graph most likely would never be centered around 50% CTR because that’d be a very high average CTR to have, so the graph should be skewed to the left. The main issue is we don’t know how much because Google gives us sampled data. The best we can do is guess. But this raises the question, what’s the right impression level to filter my keywords out to get rid of faulty data?
One way to find the right impression level to create CTR curves is to use the above method to get a feel for when your CTR distribution is getting close to a normal distribution. A Normally Distributed set of CTR data has fewer outliers and is less likely to have a high number of misreported pieces of data from Google.
3 b): Finding the best impression level to calculate CTR for your site
You can also create impression tiers to see where there’s less variability in the data you're analyzing instead of Normal Curves. The less variability in your estimates, the closer you’re getting to an accurate CTR curve.
Tiered CTR tables
Creating tiered CTR needs to be done for every site because the sampling from GSC for every site is different depending on the keywords you rank for. I’ve seen CTR curves vary as much as 30 percent without the proper controls added to CTR estimates. This step is important because using all of the data points in your CTR calculation can wildly offset your results. And using too few data points gives you too small of a sample size to get an accurate idea of what your CTR actually is. The key is to find that happy medium between the two.
In the tiered table above, there’s huge variability from All Impressions to >250 impressions. After that point though, the change per tier is fairly small. Greater than 750 impressions are the right level for this site because the variability among curves is fairly small as we increase impression levels in the other tiers and >750 impressions still gives us plenty of keywords in each ranking level of our data set.
When creating tiered CTR curves, it’s important to also count how much data is used to build each data point throughout the tiers. For smaller sites, you may find that you don’t have enough data to reliably calculate CTR curves, but that won’t be apparent from just looking at your tiered curves. So knowing the size of your data at each stage is important when deciding what impression level is the most accurate for your site.
Step 4: Decide which position methodology to analyze your data
Once you’ve figured out the correct impression-level you want to filter your data by you can start actually calculating CTR curves using impression, click, and position data. The problem with position data is that it’s often inaccurate, so if you have great keyword tracking it’s far better to use the data from your own tracking numbers than Google’s. Most people can’t track that many keyword positions so it’s necessary to use Google’s position data. That’s certainly possible, but it’s important to be careful with how we use their data.
How to use GSC position
One question that may come up when calculating CTR curves using GSC average positions is whether to use rounded positions or exact positions (i.e. only positions from GSC that rank exactly 1. So, ranks 1.0 or 2.0 are exact positions instead of 1.3 or 2.1 for example).
Exact position vs. rounded position
The reasoning behind using exact position is we want data that’s most likely to have been ranking in position 1 for the time period we’re measuring. Using exact position will give us the best idea of what CTR is at position 1. Exact rank keywords are more likely to have been ranking in that position for the duration of the time period you pulled keywords from. The problem is that Average Rank is an average so there’s no way to know if a keyword has ranked solidly in one place for a full time period or the average just happens to show an exact rank.
Fortunately, if we compare exact position CTR vs rounded position CTR, they’re directionally similar in terms of actual CTR estimations with enough data. The problem is that exact position can be volatile when you don’t have enough data. By using rounded positions we get much more data, so it makes sense to use rounded position when not enough data is available for exact position.
The one caveat is for position 1 CTR estimates. For every other position average rankings can pull up on a keywords average ranking position and at the same time they can pull down the average. Meaning that if a keyword has an average ranking of 3. It could have ranked #1 and #5 at some point and the average was 3. However, for #1 ranks, the average can only be brought down which means that the CTR for a keyword is always going to be reported lower than reality if you use rounded position.
A rank position hybrid: Adjusted exact position
So if you have enough data, only use exact position for position 1. For smaller sites, you can use adjusted exact position. Since Google gives averages up to two decimal points, one way to get more “exact position” #1s is to include all keywords which rank below position 1.1. I find this gets a couple hundred extra keywords which makes my data more reliable.
And this also shouldn’t pull down our average much at all, since GSC is somewhat inaccurate with how it reports Average Ranking. At Wayfair, we use STAT as our keyword rank tracking tool and after comparing the difference between GSC average rankings with average rankings from STAT the rankings near #1 position are close, but not 100 percent accurate. Once you start going farther down in rankings the difference between STAT and GSC become larger, so watch out how far down in the rankings you go to include more keywords in your data set.
I’ve done this analysis for all the rankings tracked on Wayfair and I found the lower the position, the less closely rankings matched between the two tools. So Google isn’t giving great rankings data, but it’s close enough near the #1 position, that I’m comfortable using adjusted exact position to increase my data set without worrying about sacrificing data quality within reason.
Conclusion
GSC is an imperfect tool, but it gives SEOs the best information we have to understand an individual site's click performance in the SERPs. Since we know that GSC is going to throw us a few curveballs with the data it provides its important to control as many pieces of that data as possible. The main ways to do so is to choose your ideal data extraction source, get rid of low impression keywords, and use the right rank rounding methods. If you do all of these things you’re much more likely to get more accurate, consistent CTR curves on your own site.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
#túi_giấy_epacking_việt_nam #túi_giấy_epacking #in_túi_giấy_giá_rẻ #in_túi_giấy #epackingvietnam #tuigiayepacking
0 notes
Text
The Data You’re Using to Calculate CTR is Wrong and Here’s Why
Posted by Luca-Bares
Click Through Rate (CTR) is an important metric that’s useful for making a lot of calculations about your site’s SEO performance, from estimating revenue opportunity, prioritize keyword optimization, to the impact of SERP changes within the market. Most SEOs know the value of creating custom CTR curves for their sites to make those projections more accurate. The only problem with custom CTR curves from Google Search Console (GSC) data is that GSC is known to be a flawed tool that can give out inaccurate data. This convolutes the data we get from GSC and can make it difficult to accurately interpret the CTR curves we create from this tool. Fortunately, there are ways to help control for these inaccuracies so you get a much clearer picture of what your data says.
By carefully cleaning your data and thoughtfully implementing an analysis methodology, you can calculate CTR for your site much more accurately using 4 basic steps:
Extract your sites keyword data from GSC — the more data you can get, the better.
Remove biased keywords — Branded search terms can throw off your CTR curves so they should be removed.
Find the optimal impression level for your data set — Google samples data at low impression levels so it’s important to remove keywords that Google may be inaccurately reporting at these lower levels.
Choose your rank position methodology — No data set is perfect, so you may want to change your rank classification methodology depending on the size of your keyword set.
Let’s take a quick step back
Before getting into the nitty gritty of calculating CTR curves, it’s useful to briefly cover the simplest way to calculate CTR since we’ll still be using this principle.
To calculate CTR, download the keywords your site ranks for with click, impression, and position data. Then take the sum of clicks divided by the sum of impressions at each rank level from GSC data you’ll come out with a custom CTR curve. For more detail on actually crunching the numbers for CTR curves, you can check out this article by SEER if you’re not familiar with the process.
Where this calculation gets tricky is when you start to try to control for the bias that inherently comes with CTR data. However, even though we know it gives bad data we don’t really have many other options, so our only option is to try to eliminate as much bias as possible in our data set and be aware of some of the problems that come from using that data.
Without controlling and manipulating the data that comes from GSC, you can get results that seem illogical. For instance, you may find your curves show position 2 and 3 CTR’s having wildly larger averages than position 1. If you don’t know that data that you’re using from Search Console is flawed you might accept that data as truth and a) try to come up with hypotheses as to why the CTR curves look that way based on incorrect data, and b) create inaccurate estimates and projections based on those CTR curves.
Step 1: Pull your data
The first part of any analysis is actually pulling the data. This data ultimately comes from GSC, but there are many platforms that you can pull this data from that are better than GSC's web extraction.
Google Search Console — The easiest platform to get the data from is from GSC itself. You can go into GSC and pull all your keyword data for the last three months. Google will automatically download a csv. file for you. The downside to this method is that GSC only exports 1,000 keywords at a time making your data size much too small for analysis. You can try to get around this by using the keyword filter for the head terms that you rank for and downloading multiple 1k files to get more data, but this process is an arduous one. Besides the other methods listed below are better and easier.
Google Data Studio — For any non-programmer looking for an easy way to get much more data from Search Console for free, this is definitely your best option. Google Data Studio connects directly to your GSC account data, but there are no limitations on the data size you can pull. For the same three month period trying to pull data from GSC where I would get 1k keywords (the max in GSC), Data Studio would give me back 200k keywords!
Google Search Console API — This takes some programming know-how, but one of the best ways to get the data you’re looking for is to connect directly to the source using their API. You’ll have much more control over the data you’re pulling and get a fairly large data set. The main setback here is you need to have the programming knowledge or resources to do so.
Keylime SEO Toolbox — If you don’t know how to program but still want access to Google’s impression and click data, then this is a great option to consider. Keylime stores historical Search Console data directly from the Search Console API so it’s as good (if not better) of an option than directly connecting to the API. It does cost $49/mo, but that’s pretty affordable considering the value of the data you’re getting.
The reason it’s important what platform you get your data from is that each one listed gives out different amounts of data. I’ve listed them here in the order of which tool gives the most data from least to most. Using GSC’s UI directly gives by far the least data, while Keylime can connect to GSC and Google Analytics to combine data to actually give you more information than the Search Console API would give you. This is good because whenever you can get more data, the more likely that the CTR averages you’re going to make for your site are going to be accurate.
Step 2: Remove keyword bias
Once you’ve pulled the data, you have to clean it. Because this data ultimately comes from Search Console we have to make sure we clean the data as best we can.
Remove branded search & knowledge graph keywords
When you create general CTR curves for non-branded search it’s important to remove all branded keywords from your data. These keywords should have high CTR’s which will throw off the averages of your non-branded searches which is why they should be removed. In addition, if you’re aware of any SERP features like knowledge graph you rank for consistently, you should try to remove those as well since we’re only calculating CTR for positions 1–10 and SERP feature keywords could throw off your averages.
Step 3: Find the optimal impression level in GSC for your data
The largest bias from Search Console data appears to come from data with low search impressions which is the data we need to try and remove. It’s not surprising that Google doesn’t accurately report low impression data since we know that Google doesn’t even include data with very low searches in GSC. For some reason Google decides to drastically over report CTR for these low impression terms. As an example, here’s an impression distribution graph I made with data from GSC for keywords that have only 1 impression and the CTR for every position.
If that doesn’t make a lot of sense to you, I’m right there with you. This graph says a majority of the keywords with only one impression has 100 percent CTR. It’s extremely unlikely, no matter how good your site’s CTR is, that one impression keywords are going to get a majority of 100 percent CTR. This is especially true for keywords that rank below #1. This gives us pretty solid evidence low impression data is not to be trusted, and we should limit the number of keywords in our data with low impressions.
Step 3 a): Use normal curves to help calculate CTR
For more evidence of Google giving us biased data we can look at the distribution of CTR for all the keywords in our data set. Since we’re calculating CTR averages, the data should adhere to a Normal Bell Curve. In most cases CTR curves from GSC are highly skewed to the left with long tails which again indicates that Google reports very high CTR at low impression volumes.
If we change the minimum number of impressions for the keyword sets that we’re analyzing we end up getting closer and closer to the center of the graph. Here’s an example, below is the distribution of a site CTR in CTR increments of .001.
The graph above shows the impressions at a very low impression level, around 25 impressions. The distribution of data is mostly on the right side of this graph with a small, high concentration on the left implies that this site has a very high click-through rate. However, by increasing the impression filter to 5,000 impressions per keyword the distribution of keywords gets much much closer to the center.
This graph most likely would never be centered around 50% CTR because that’d be a very high average CTR to have, so the graph should be skewed to the left. The main issue is we don’t know how much because Google gives us sampled data. The best we can do is guess. But this raises the question, what’s the right impression level to filter my keywords out to get rid of faulty data?
One way to find the right impression level to create CTR curves is to use the above method to get a feel for when your CTR distribution is getting close to a normal distribution. A Normally Distributed set of CTR data has fewer outliers and is less likely to have a high number of misreported pieces of data from Google.
3 b): Finding the best impression level to calculate CTR for your site
You can also create impression tiers to see where there’s less variability in the data you're analyzing instead of Normal Curves. The less variability in your estimates, the closer you’re getting to an accurate CTR curve.
Tiered CTR tables
Creating tiered CTR needs to be done for every site because the sampling from GSC for every site is different depending on the keywords you rank for. I’ve seen CTR curves vary as much as 30 percent without the proper controls added to CTR estimates. This step is important because using all of the data points in your CTR calculation can wildly offset your results. And using too few data points gives you too small of a sample size to get an accurate idea of what your CTR actually is. The key is to find that happy medium between the two.
In the tiered table above, there’s huge variability from All Impressions to >250 impressions. After that point though, the change per tier is fairly small. Greater than 750 impressions are the right level for this site because the variability among curves is fairly small as we increase impression levels in the other tiers and >750 impressions still gives us plenty of keywords in each ranking level of our data set.
When creating tiered CTR curves, it’s important to also count how much data is used to build each data point throughout the tiers. For smaller sites, you may find that you don’t have enough data to reliably calculate CTR curves, but that won’t be apparent from just looking at your tiered curves. So knowing the size of your data at each stage is important when deciding what impression level is the most accurate for your site.
Step 4: Decide which position methodology to analyze your data
Once you’ve figured out the correct impression-level you want to filter your data by you can start actually calculating CTR curves using impression, click, and position data. The problem with position data is that it’s often inaccurate, so if you have great keyword tracking it’s far better to use the data from your own tracking numbers than Google’s. Most people can’t track that many keyword positions so it’s necessary to use Google’s position data. That’s certainly possible, but it’s important to be careful with how we use their data.
How to use GSC position
One question that may come up when calculating CTR curves using GSC average positions is whether to use rounded positions or exact positions (i.e. only positions from GSC that rank exactly 1. So, ranks 1.0 or 2.0 are exact positions instead of 1.3 or 2.1 for example).
Exact position vs. rounded position
The reasoning behind using exact position is we want data that’s most likely to have been ranking in position 1 for the time period we’re measuring. Using exact position will give us the best idea of what CTR is at position 1. Exact rank keywords are more likely to have been ranking in that position for the duration of the time period you pulled keywords from. The problem is that Average Rank is an average so there’s no way to know if a keyword has ranked solidly in one place for a full time period or the average just happens to show an exact rank.
Fortunately, if we compare exact position CTR vs rounded position CTR, they’re directionally similar in terms of actual CTR estimations with enough data. The problem is that exact position can be volatile when you don’t have enough data. By using rounded positions we get much more data, so it makes sense to use rounded position when not enough data is available for exact position.
The one caveat is for position 1 CTR estimates. For every other position average rankings can pull up on a keywords average ranking position and at the same time they can pull down the average. Meaning that if a keyword has an average ranking of 3. It could have ranked #1 and #5 at some point and the average was 3. However, for #1 ranks, the average can only be brought down which means that the CTR for a keyword is always going to be reported lower than reality if you use rounded position.
A rank position hybrid: Adjusted exact position
So if you have enough data, only use exact position for position 1. For smaller sites, you can use adjusted exact position. Since Google gives averages up to two decimal points, one way to get more “exact position” #1s is to include all keywords which rank below position 1.1. I find this gets a couple hundred extra keywords which makes my data more reliable.
And this also shouldn’t pull down our average much at all, since GSC is somewhat inaccurate with how it reports Average Ranking. At Wayfair, we use STAT as our keyword rank tracking tool and after comparing the difference between GSC average rankings with average rankings from STAT the rankings near #1 position are close, but not 100 percent accurate. Once you start going farther down in rankings the difference between STAT and GSC become larger, so watch out how far down in the rankings you go to include more keywords in your data set.
I’ve done this analysis for all the rankings tracked on Wayfair and I found the lower the position, the less closely rankings matched between the two tools. So Google isn’t giving great rankings data, but it’s close enough near the #1 position, that I’m comfortable using adjusted exact position to increase my data set without worrying about sacrificing data quality within reason.
Conclusion
GSC is an imperfect tool, but it gives SEOs the best information we have to understand an individual site's click performance in the SERPs. Since we know that GSC is going to throw us a few curveballs with the data it provides its important to control as many pieces of that data as possible. The main ways to do so is to choose your ideal data extraction source, get rid of low impression keywords, and use the right rank rounding methods. If you do all of these things you’re much more likely to get more accurate, consistent CTR curves on your own site.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog http://tracking.feedpress.it/link/9375/12806628
0 notes
Text
The Data You’re Using to Calculate CTR is Wrong and Here’s Why
Posted by Luca-Bares
Click Through Rate (CTR) is an important metric that’s useful for making a lot of calculations about your site’s SEO performance, from estimating revenue opportunity, prioritize keyword optimization, to the impact of SERP changes within the market. Most SEOs know the value of creating custom CTR curves for their sites to make those projections more accurate. The only problem with custom CTR curves from Google Search Console (GSC) data is that GSC is known to be a flawed tool that can give out inaccurate data. This convolutes the data we get from GSC and can make it difficult to accurately interpret the CTR curves we create from this tool. Fortunately, there are ways to help control for these inaccuracies so you get a much clearer picture of what your data says.
By carefully cleaning your data and thoughtfully implementing an analysis methodology, you can calculate CTR for your site much more accurately using 4 basic steps:
Extract your sites keyword data from GSC — the more data you can get, the better.
Remove biased keywords — Branded search terms can throw off your CTR curves so they should be removed.
Find the optimal impression level for your data set — Google samples data at low impression levels so it’s important to remove keywords that Google may be inaccurately reporting at these lower levels.
Choose your rank position methodology — No data set is perfect, so you may want to change your rank classification methodology depending on the size of your keyword set.
Let’s take a quick step back
Before getting into the nitty gritty of calculating CTR curves, it’s useful to briefly cover the simplest way to calculate CTR since we’ll still be using this principle.
To calculate CTR, download the keywords your site ranks for with click, impression, and position data. Then take the sum of clicks divided by the sum of impressions at each rank level from GSC data you’ll come out with a custom CTR curve. For more detail on actually crunching the numbers for CTR curves, you can check out this article by SEER if you’re not familiar with the process.
Where this calculation gets tricky is when you start to try to control for the bias that inherently comes with CTR data. However, even though we know it gives bad data we don’t really have many other options, so our only option is to try to eliminate as much bias as possible in our data set and be aware of some of the problems that come from using that data.
Without controlling and manipulating the data that comes from GSC, you can get results that seem illogical. For instance, you may find your curves show position 2 and 3 CTR’s having wildly larger averages than position 1. If you don’t know that data that you’re using from Search Console is flawed you might accept that data as truth and a) try to come up with hypotheses as to why the CTR curves look that way based on incorrect data, and b) create inaccurate estimates and projections based on those CTR curves.
Step 1: Pull your data
The first part of any analysis is actually pulling the data. This data ultimately comes from GSC, but there are many platforms that you can pull this data from that are better than GSC's web extraction.
Google Search Console — The easiest platform to get the data from is from GSC itself. You can go into GSC and pull all your keyword data for the last three months. Google will automatically download a csv. file for you. The downside to this method is that GSC only exports 1,000 keywords at a time making your data size much too small for analysis. You can try to get around this by using the keyword filter for the head terms that you rank for and downloading multiple 1k files to get more data, but this process is an arduous one. Besides the other methods listed below are better and easier.
Google Data Studio — For any non-programmer looking for an easy way to get much more data from Search Console for free, this is definitely your best option. Google Data Studio connects directly to your GSC account data, but there are no limitations on the data size you can pull. For the same three month period trying to pull data from GSC where I would get 1k keywords (the max in GSC), Data Studio would give me back 200k keywords!
Google Search Console API — This takes some programming know-how, but one of the best ways to get the data you’re looking for is to connect directly to the source using their API. You’ll have much more control over the data you’re pulling and get a fairly large data set. The main setback here is you need to have the programming knowledge or resources to do so.
Keylime SEO Toolbox — If you don’t know how to program but still want access to Google’s impression and click data, then this is a great option to consider. Keylime stores historical Search Console data directly from the Search Console API so it’s as good (if not better) of an option than directly connecting to the API. It does cost $49/mo, but that’s pretty affordable considering the value of the data you’re getting.
The reason it’s important what platform you get your data from is that each one listed gives out different amounts of data. I’ve listed them here in the order of which tool gives the most data from least to most. Using GSC’s UI directly gives by far the least data, while Keylime can connect to GSC and Google Analytics to combine data to actually give you more information than the Search Console API would give you. This is good because whenever you can get more data, the more likely that the CTR averages you’re going to make for your site are going to be accurate.
Step 2: Remove keyword bias
Once you’ve pulled the data, you have to clean it. Because this data ultimately comes from Search Console we have to make sure we clean the data as best we can.
Remove branded search & knowledge graph keywords
When you create general CTR curves for non-branded search it’s important to remove all branded keywords from your data. These keywords should have high CTR’s which will throw off the averages of your non-branded searches which is why they should be removed. In addition, if you’re aware of any SERP features like knowledge graph you rank for consistently, you should try to remove those as well since we’re only calculating CTR for positions 1–10 and SERP feature keywords could throw off your averages.
Step 3: Find the optimal impression level in GSC for your data
The largest bias from Search Console data appears to come from data with low search impressions which is the data we need to try and remove. It’s not surprising that Google doesn’t accurately report low impression data since we know that Google doesn’t even include data with very low searches in GSC. For some reason Google decides to drastically over report CTR for these low impression terms. As an example, here’s an impression distribution graph I made with data from GSC for keywords that have only 1 impression and the CTR for every position.
If that doesn’t make a lot of sense to you, I’m right there with you. This graph says a majority of the keywords with only one impression has 100 percent CTR. It’s extremely unlikely, no matter how good your site’s CTR is, that one impression keywords are going to get a majority of 100 percent CTR. This is especially true for keywords that rank below #1. This gives us pretty solid evidence low impression data is not to be trusted, and we should limit the number of keywords in our data with low impressions.
Step 3 a): Use normal curves to help calculate CTR
For more evidence of Google giving us biased data we can look at the distribution of CTR for all the keywords in our data set. Since we’re calculating CTR averages, the data should adhere to a Normal Bell Curve. In most cases CTR curves from GSC are highly skewed to the left with long tails which again indicates that Google reports very high CTR at low impression volumes.
If we change the minimum number of impressions for the keyword sets that we’re analyzing we end up getting closer and closer to the center of the graph. Here’s an example, below is the distribution of a site CTR in CTR increments of .001.
The graph above shows the impressions at a very low impression level, around 25 impressions. The distribution of data is mostly on the right side of this graph with a small, high concentration on the left implies that this site has a very high click-through rate. However, by increasing the impression filter to 5,000 impressions per keyword the distribution of keywords gets much much closer to the center.
This graph most likely would never be centered around 50% CTR because that’d be a very high average CTR to have, so the graph should be skewed to the left. The main issue is we don’t know how much because Google gives us sampled data. The best we can do is guess. But this raises the question, what’s the right impression level to filter my keywords out to get rid of faulty data?
One way to find the right impression level to create CTR curves is to use the above method to get a feel for when your CTR distribution is getting close to a normal distribution. A Normally Distributed set of CTR data has fewer outliers and is less likely to have a high number of misreported pieces of data from Google.
3 b): Finding the best impression level to calculate CTR for your site
You can also create impression tiers to see where there’s less variability in the data you're analyzing instead of Normal Curves. The less variability in your estimates, the closer you’re getting to an accurate CTR curve.
Tiered CTR tables
Creating tiered CTR needs to be done for every site because the sampling from GSC for every site is different depending on the keywords you rank for. I’ve seen CTR curves vary as much as 30 percent without the proper controls added to CTR estimates. This step is important because using all of the data points in your CTR calculation can wildly offset your results. And using too few data points gives you too small of a sample size to get an accurate idea of what your CTR actually is. The key is to find that happy medium between the two.
In the tiered table above, there’s huge variability from All Impressions to >250 impressions. After that point though, the change per tier is fairly small. Greater than 750 impressions are the right level for this site because the variability among curves is fairly small as we increase impression levels in the other tiers and >750 impressions still gives us plenty of keywords in each ranking level of our data set.
When creating tiered CTR curves, it’s important to also count how much data is used to build each data point throughout the tiers. For smaller sites, you may find that you don’t have enough data to reliably calculate CTR curves, but that won’t be apparent from just looking at your tiered curves. So knowing the size of your data at each stage is important when deciding what impression level is the most accurate for your site.
Step 4: Decide which position methodology to analyze your data
Once you’ve figured out the correct impression-level you want to filter your data by you can start actually calculating CTR curves using impression, click, and position data. The problem with position data is that it’s often inaccurate, so if you have great keyword tracking it’s far better to use the data from your own tracking numbers than Google’s. Most people can’t track that many keyword positions so it’s necessary to use Google’s position data. That’s certainly possible, but it’s important to be careful with how we use their data.
How to use GSC position
One question that may come up when calculating CTR curves using GSC average positions is whether to use rounded positions or exact positions (i.e. only positions from GSC that rank exactly 1. So, ranks 1.0 or 2.0 are exact positions instead of 1.3 or 2.1 for example).
Exact position vs. rounded position
The reasoning behind using exact position is we want data that’s most likely to have been ranking in position 1 for the time period we’re measuring. Using exact position will give us the best idea of what CTR is at position 1. Exact rank keywords are more likely to have been ranking in that position for the duration of the time period you pulled keywords from. The problem is that Average Rank is an average so there’s no way to know if a keyword has ranked solidly in one place for a full time period or the average just happens to show an exact rank.
Fortunately, if we compare exact position CTR vs rounded position CTR, they’re directionally similar in terms of actual CTR estimations with enough data. The problem is that exact position can be volatile when you don’t have enough data. By using rounded positions we get much more data, so it makes sense to use rounded position when not enough data is available for exact position.
The one caveat is for position 1 CTR estimates. For every other position average rankings can pull up on a keywords average ranking position and at the same time they can pull down the average. Meaning that if a keyword has an average ranking of 3. It could have ranked #1 and #5 at some point and the average was 3. However, for #1 ranks, the average can only be brought down which means that the CTR for a keyword is always going to be reported lower than reality if you use rounded position.
A rank position hybrid: Adjusted exact position
So if you have enough data, only use exact position for position 1. For smaller sites, you can use adjusted exact position. Since Google gives averages up to two decimal points, one way to get more “exact position” #1s is to include all keywords which rank below position 1.1. I find this gets a couple hundred extra keywords which makes my data more reliable.
And this also shouldn’t pull down our average much at all, since GSC is somewhat inaccurate with how it reports Average Ranking. At Wayfair, we use STAT as our keyword rank tracking tool and after comparing the difference between GSC average rankings with average rankings from STAT the rankings near #1 position are close, but not 100 percent accurate. Once you start going farther down in rankings the difference between STAT and GSC become larger, so watch out how far down in the rankings you go to include more keywords in your data set.
I’ve done this analysis for all the rankings tracked on Wayfair and I found the lower the position, the less closely rankings matched between the two tools. So Google isn’t giving great rankings data, but it’s close enough near the #1 position, that I’m comfortable using adjusted exact position to increase my data set without worrying about sacrificing data quality within reason.
Conclusion
GSC is an imperfect tool, but it gives SEOs the best information we have to understand an individual site's click performance in the SERPs. Since we know that GSC is going to throw us a few curveballs with the data it provides its important to control as many pieces of that data as possible. The main ways to do so is to choose your ideal data extraction source, get rid of low impression keywords, and use the right rank rounding methods. If you do all of these things you’re much more likely to get more accurate, consistent CTR curves on your own site.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
from The Moz Blog https://ift.tt/3168gmA via IFTTT
0 notes
Text
The Data You’re Using to Calculate CTR is Wrong and Here’s Why
Posted by Luca-Bares
Click Through Rate (CTR) is an important metric that’s useful for making a lot of calculations about your site’s SEO performance, from estimating revenue opportunity, prioritize keyword optimization, to the impact of SERP changes within the market. Most SEOs know the value of creating custom CTR curves for their sites to make those projections more accurate. The only problem with custom CTR curves from Google Search Console (GSC) data is that GSC is known to be a flawed tool that can give out inaccurate data. This convolutes the data we get from GSC and can make it difficult to accurately interpret the CTR curves we create from this tool. Fortunately, there are ways to help control for these inaccuracies so you get a much clearer picture of what your data says.
By carefully cleaning your data and thoughtfully implementing an analysis methodology, you can calculate CTR for your site much more accurately using 4 basic steps:
Extract your sites keyword data from GSC — the more data you can get, the better.
Remove biased keywords — Branded search terms can throw off your CTR curves so they should be removed.
Find the optimal impression level for your data set — Google samples data at low impression levels so it’s important to remove keywords that Google may be inaccurately reporting at these lower levels.
Choose your rank position methodology — No data set is perfect, so you may want to change your rank classification methodology depending on the size of your keyword set.
Let’s take a quick step back
Before getting into the nitty gritty of calculating CTR curves, it’s useful to briefly cover the simplest way to calculate CTR since we’ll still be using this principle.
To calculate CTR, download the keywords your site ranks for with click, impression, and position data. Then take the sum of clicks divided by the sum of impressions at each rank level from GSC data you’ll come out with a custom CTR curve. For more detail on actually crunching the numbers for CTR curves, you can check out this article by SEER if you’re not familiar with the process.
Where this calculation gets tricky is when you start to try to control for the bias that inherently comes with CTR data. However, even though we know it gives bad data we don’t really have many other options, so our only option is to try to eliminate as much bias as possible in our data set and be aware of some of the problems that come from using that data.
Without controlling and manipulating the data that comes from GSC, you can get results that seem illogical. For instance, you may find your curves show position 2 and 3 CTR’s having wildly larger averages than position 1. If you don’t know that data that you’re using from Search Console is flawed you might accept that data as truth and a) try to come up with hypotheses as to why the CTR curves look that way based on incorrect data, and b) create inaccurate estimates and projections based on those CTR curves.
Step 1: Pull your data
The first part of any analysis is actually pulling the data. This data ultimately comes from GSC, but there are many platforms that you can pull this data from that are better than GSC's web extraction.
Google Search Console — The easiest platform to get the data from is from GSC itself. You can go into GSC and pull all your keyword data for the last three months. Google will automatically download a csv. file for you. The downside to this method is that GSC only exports 1,000 keywords at a time making your data size much too small for analysis. You can try to get around this by using the keyword filter for the head terms that you rank for and downloading multiple 1k files to get more data, but this process is an arduous one. Besides the other methods listed below are better and easier.
Google Data Studio — For any non-programmer looking for an easy way to get much more data from Search Console for free, this is definitely your best option. Google Data Studio connects directly to your GSC account data, but there are no limitations on the data size you can pull. For the same three month period trying to pull data from GSC where I would get 1k keywords (the max in GSC), Data Studio would give me back 200k keywords!
Google Search Console API — This takes some programming know-how, but one of the best ways to get the data you’re looking for is to connect directly to the source using their API. You’ll have much more control over the data you’re pulling and get a fairly large data set. The main setback here is you need to have the programming knowledge or resources to do so.
Keylime SEO Toolbox — If you don’t know how to program but still want access to Google’s impression and click data, then this is a great option to consider. Keylime stores historical Search Console data directly from the Search Console API so it’s as good (if not better) of an option than directly connecting to the API. It does cost $49/mo, but that’s pretty affordable considering the value of the data you’re getting.
The reason it’s important what platform you get your data from is that each one listed gives out different amounts of data. I’ve listed them here in the order of which tool gives the most data from least to most. Using GSC’s UI directly gives by far the least data, while Keylime can connect to GSC and Google Analytics to combine data to actually give you more information than the Search Console API would give you. This is good because whenever you can get more data, the more likely that the CTR averages you’re going to make for your site are going to be accurate.
Step 2: Remove keyword bias
Once you’ve pulled the data, you have to clean it. Because this data ultimately comes from Search Console we have to make sure we clean the data as best we can.
Remove branded search & knowledge graph keywords
When you create general CTR curves for non-branded search it’s important to remove all branded keywords from your data. These keywords should have high CTR’s which will throw off the averages of your non-branded searches which is why they should be removed. In addition, if you’re aware of any SERP features like knowledge graph you rank for consistently, you should try to remove those as well since we’re only calculating CTR for positions 1–10 and SERP feature keywords could throw off your averages.
Step 3: Find the optimal impression level in GSC for your data
The largest bias from Search Console data appears to come from data with low search impressions which is the data we need to try and remove. It’s not surprising that Google doesn’t accurately report low impression data since we know that Google doesn’t even include data with very low searches in GSC. For some reason Google decides to drastically over report CTR for these low impression terms. As an example, here’s an impression distribution graph I made with data from GSC for keywords that have only 1 impression and the CTR for every position.
If that doesn’t make a lot of sense to you, I’m right there with you. This graph says a majority of the keywords with only one impression has 100 percent CTR. It’s extremely unlikely, no matter how good your site’s CTR is, that one impression keywords are going to get a majority of 100 percent CTR. This is especially true for keywords that rank below #1. This gives us pretty solid evidence low impression data is not to be trusted, and we should limit the number of keywords in our data with low impressions.
Step 3 a): Use normal curves to help calculate CTR
For more evidence of Google giving us biased data we can look at the distribution of CTR for all the keywords in our data set. Since we’re calculating CTR averages, the data should adhere to a Normal Bell Curve. In most cases CTR curves from GSC are highly skewed to the left with long tails which again indicates that Google reports very high CTR at low impression volumes.
If we change the minimum number of impressions for the keyword sets that we’re analyzing we end up getting closer and closer to the center of the graph. Here’s an example, below is the distribution of a site CTR in CTR increments of .001.
The graph above shows the impressions at a very low impression level, around 25 impressions. The distribution of data is mostly on the right side of this graph with a small, high concentration on the left implies that this site has a very high click-through rate. However, by increasing the impression filter to 5,000 impressions per keyword the distribution of keywords gets much much closer to the center.
This graph most likely would never be centered around 50% CTR because that’d be a very high average CTR to have, so the graph should be skewed to the left. The main issue is we don’t know how much because Google gives us sampled data. The best we can do is guess. But this raises the question, what’s the right impression level to filter my keywords out to get rid of faulty data?
One way to find the right impression level to create CTR curves is to use the above method to get a feel for when your CTR distribution is getting close to a normal distribution. A Normally Distributed set of CTR data has fewer outliers and is less likely to have a high number of misreported pieces of data from Google.
3 b): Finding the best impression level to calculate CTR for your site
You can also create impression tiers to see where there’s less variability in the data you're analyzing instead of Normal Curves. The less variability in your estimates, the closer you’re getting to an accurate CTR curve.
Tiered CTR tables
Creating tiered CTR needs to be done for every site because the sampling from GSC for every site is different depending on the keywords you rank for. I’ve seen CTR curves vary as much as 30 percent without the proper controls added to CTR estimates. This step is important because using all of the data points in your CTR calculation can wildly offset your results. And using too few data points gives you too small of a sample size to get an accurate idea of what your CTR actually is. The key is to find that happy medium between the two.
In the tiered table above, there’s huge variability from All Impressions to >250 impressions. After that point though, the change per tier is fairly small. Greater than 750 impressions are the right level for this site because the variability among curves is fairly small as we increase impression levels in the other tiers and >750 impressions still gives us plenty of keywords in each ranking level of our data set.
When creating tiered CTR curves, it’s important to also count how much data is used to build each data point throughout the tiers. For smaller sites, you may find that you don’t have enough data to reliably calculate CTR curves, but that won’t be apparent from just looking at your tiered curves. So knowing the size of your data at each stage is important when deciding what impression level is the most accurate for your site.
Step 4: Decide which position methodology to analyze your data
Once you’ve figured out the correct impression-level you want to filter your data by you can start actually calculating CTR curves using impression, click, and position data. The problem with position data is that it’s often inaccurate, so if you have great keyword tracking it’s far better to use the data from your own tracking numbers than Google’s. Most people can’t track that many keyword positions so it’s necessary to use Google’s position data. That’s certainly possible, but it’s important to be careful with how we use their data.
How to use GSC position
One question that may come up when calculating CTR curves using GSC average positions is whether to use rounded positions or exact positions (i.e. only positions from GSC that rank exactly 1. So, ranks 1.0 or 2.0 are exact positions instead of 1.3 or 2.1 for example).
Exact position vs. rounded position
The reasoning behind using exact position is we want data that’s most likely to have been ranking in position 1 for the time period we’re measuring. Using exact position will give us the best idea of what CTR is at position 1. Exact rank keywords are more likely to have been ranking in that position for the duration of the time period you pulled keywords from. The problem is that Average Rank is an average so there’s no way to know if a keyword has ranked solidly in one place for a full time period or the average just happens to show an exact rank.
Fortunately, if we compare exact position CTR vs rounded position CTR, they’re directionally similar in terms of actual CTR estimations with enough data. The problem is that exact position can be volatile when you don’t have enough data. By using rounded positions we get much more data, so it makes sense to use rounded position when not enough data is available for exact position.
The one caveat is for position 1 CTR estimates. For every other position average rankings can pull up on a keywords average ranking position and at the same time they can pull down the average. Meaning that if a keyword has an average ranking of 3. It could have ranked #1 and #5 at some point and the average was 3. However, for #1 ranks, the average can only be brought down which means that the CTR for a keyword is always going to be reported lower than reality if you use rounded position.
A rank position hybrid: Adjusted exact position
So if you have enough data, only use exact position for position 1. For smaller sites, you can use adjusted exact position. Since Google gives averages up to two decimal points, one way to get more “exact position” #1s is to include all keywords which rank below position 1.1. I find this gets a couple hundred extra keywords which makes my data more reliable.
And this also shouldn’t pull down our average much at all, since GSC is somewhat inaccurate with how it reports Average Ranking. At Wayfair, we use STAT as our keyword rank tracking tool and after comparing the difference between GSC average rankings with average rankings from STAT the rankings near #1 position are close, but not 100 percent accurate. Once you start going farther down in rankings the difference between STAT and GSC become larger, so watch out how far down in the rankings you go to include more keywords in your data set.
I’ve done this analysis for all the rankings tracked on Wayfair and I found the lower the position, the less closely rankings matched between the two tools. So Google isn’t giving great rankings data, but it’s close enough near the #1 position, that I’m comfortable using adjusted exact position to increase my data set without worrying about sacrificing data quality within reason.
Conclusion
GSC is an imperfect tool, but it gives SEOs the best information we have to understand an individual site's click performance in the SERPs. Since we know that GSC is going to throw us a few curveballs with the data it provides its important to control as many pieces of that data as possible. The main ways to do so is to choose your ideal data extraction source, get rid of low impression keywords, and use the right rank rounding methods. If you do all of these things you’re much more likely to get more accurate, consistent CTR curves on your own site.
Sign up for The Moz Top 10, a semimonthly mailer updating you on the top ten hottest pieces of SEO news, tips, and rad links uncovered by the Moz team. Think of it as your exclusive digest of stuff you don't have time to hunt down but want to read!
0 notes